How Query Engines Work 中文版
阅读地址: https://query.arktoria.org
英文原版: https://howqueryengineswork.com/
原文许可:Copyright © 2020-2023 Andy Grove. All rights reserved
译文许可:Creative Commons Attribution-ShareAlike 4.0 International License
本人水平有限,有异议或补充的地方可以邮件形式告知,或在 Issues 中提出并参与讨论。 ——译者:Ariel AxionL (艾雨寒)
Acknowledgments 致谢
如果没有我家人的支持,这本书也不可能完成,但我沉浸在这个附属项目中的时候,他们给予了我极大的耐心。
特别感谢 Matthew Powers,又名 Mr.Powers,他在一开始就激发了我写这本书的灵感。Matthew 是 《Writing Beautiful Apache Spark Code》的作者,这本书也可以在 Leanpub 上找到。
同样也得感谢在过去几年从事 DataFusion 项目期间与我有过互动的无数人,特别是 Apache Arrow PMC、以及其他的提交者和贡献者。
最后,我要感谢在 RMS 工作期间 Chris George 和 Joe Buszkiewic 对我的支持和鼓励,在那里我进一步加深了对查询引擎的理解。
这本书也可以在 https://leanpub.com/how-query-engines-work 以 ePub、MOBI 和 PDF 格式购买。
Copyright © 2020-2023 Andy Grove. All rights reserved.
Introduction 介绍
我自从开始第一份软件工程师的工作以来,一直痴迷于数据库和查询语言。向计算机提问并且高效地获取有用的数据是一件非常神奇的事情。在做了多年的常规软件开发人员和数据技术的终端用户后,我开始为一家初创公司工作,这让我深入了解分布式数据开发。这是一本我开始这段旅程之前就已经存在的书。尽管它只是一本入门级的书,当我希望能够揭开查询引擎工作原理的神秘面纱。
我对于查询引擎的性质最终致使我参与了 Apache Arrow 项目,在该项目中,我在 2018 年贡献了最初的 Rust 实现,然后再 2019 年贡献了 DataFusion 内存式查询引擎,最终在 2021 年贡献了 Ballista 分布式计算项目。
在 Rust 实现方面,Arrow 项目现在有着许多活跃的提交者和贡献者,并且与我最初贡献的版本相比,它有了显著的改进。
尽管对于高性能查询引擎而言,Rust 语言是一个不错的选择,但它并不适合教授关于查询引擎的概念,因此我最近在写这本书的适合用 Kotlin 实现了一个新的查询引擎。Kotlin 是一门非常简洁易读的语言,因此可以子啊本书中包含源代码示例。我将鼓励您在阅读本书的过程中熟悉源代码,并考虑做出一些贡献。没有什么是比实践更好的学习方法了。
本书中涉及的查询引擎最初是打算作为 Ballista 项目的一部分(并且持续了一段时间),但随着项目的发展,很明显,通过 UDF(用户定义函数) 机制将查询引擎保留在 Rust 中并支持 Java 和其它语言将更有意义,而不是在多种语言中重复大量的查询执行逻辑。
现在 Ballista 项目已经贡献给了 Apache Arrow,我已经将这本书中配套代码库中的查询引擎简单地称为 "KQuery",是 Kotlin Query Engine 的简称,但如果有人有更好的名称建议,请告诉我。
这本书的后续篇章将可用版本更新时免费提供,因此请偶尔查看本书地址或者在 Twitter 上关注我 (@andygrove_io) 以便接收新内容可用通知。
Feedback 反馈
如果您对本书有任何反馈,可以给我的 Twitter 账户 @andygrove_io 发送站内信或者向 agrove@apache.org 发送邮件。
What Is a Query Engine? 什么是查询引擎?
查询引擎是一种软件,它可以对数据进行查询,以产生问题的答案,例如:
- 今年到目前为止,我每月的平均销售额是多少?
- 在过去的一天里,我的网站上最受欢迎的五个网页是什么?
- 与一年前相比,网络流量的月度情况如何?
最广泛使用的查询语言是结构化查询语言 (简称 SQL)。许多开发人员在他们的职业生涯中都会遇到关系型数据库,如 MySQL、Postgres、Oracle 或 SQL Server。所有这些数据库都包含支持 SQL 的查询引擎。
这里有一些 SQL 请求示例:
SQL 示例:月平均销售额
SELECT month, AVG(sales)
FROM product_sales
WHERE year = 2020
GROUP BY month;
SQL 示例:昨天最热门的五个网页
SELECT page_url, COUNT(*) AS num_visits
FROM apache_log
WHERE event_date = yesterday()
GROUP BY page_url
ORDER BY num_visits DESC
LIMIT 5;
SQL 功能强大且广为人知,但在所谓的 “大数据” 世界中存在局限性,数据科学家通常需要将自定义代码和查询混合在一起。Apache Hadoop、Apache Hive 和 Apache Spark 等平台和工具现在被广泛用于查询和操作大量数据。
Apache Spark 使用 DataFrame 查询示例:
val spark: SparkSession = SparkSession.builder
.appName("Example")
.master("local[*]")
.getOrCreate()
val df = spark.read.parquet("/mnt/nyctaxi/parquet")
.groupBy("passenger_count")
.sum("fare_amount")
.orderBy("passenger_count")
df.show()
Why Are Query Engines Popular? 为什么查询引擎广受欢迎?
数据增长的加速度越来越大,通常无法在一台计算机上容纳。需要专业的工程师来编写分布式代码以查询数据,并且每次需要从数据中获取新答案时都编写自定义代码是不切实际的。查询引擎提供了一组标准操作和转换方式,因此终端用户可以通过以不同方式将简单的查询语言或应用程序编程接口 (API) 进行组合和转换,并进行调优以获得良好的性能。
What This Book Covers 本书涵盖了什么内容
本书概述了构建通用查询引擎所涉及的每个步骤。本书中讨论的查询引擎是专门为本书开发的一个简单的查询疫情,其代码是在编写本书内容的同时开发的,以确保我在面临涉及决策时可以编写有关的主题内容。
Source Code 源代码
本书所讨论的完整的查询引擎代码在 Github 仓库:
https://github.com/andygrove/how-query-engines-work
有关使用 Gradle 构建项目的最新说明请参阅项目中的 README 文档。
Why Kotlin? 为什么使用 Kotlin?
本书的重点是查询引擎设计,这通常是编程语言不可或缺的。我在本书中之所以选择 Kotlin,是因为它简洁易懂。并且它也与 Java 100% 兼容,这意味着您可以从 Java 或者其它基于 Java 的语言 (比如 Scala) 调用 Kotlin 代码。
尽管如此,Apache Arrow 项目中的 DataFusion 查询引擎也主要是基于本书中的设计。对 Rust 比 JVM 更感兴趣的读者可以参考 DataFusion 源代码和本书。
Apache Arrow
Apache Arrow 最开始是作为列式数据的内存规范,并以 Java 和 C++ 进行实现。这种内存格式对于支持 SIMD (单指令,多数据) 的 CPU 和 GPU 等现代硬件的矢量化处理是非常有效率的的。
采用标准化的数据内存格式有以下几个好处:
-
如 Python 或 Java 等高级语言可以通过传递数据指针来调用 Rust 或 C++ 等低级语言来完成计算密集型任务,而不是以另一种格式复制数据,这样造成的开销会非常大。
-
由于内存格式也是网络传输格式 (尽管数据也能被压缩),数据可以在进程之间有效的地传输,而不需要太多的序列化开销。
-
它应该能让数据科学和数据分析领域的各种开源和商业项目之间构建连接器、驱动程序和集成变得更加容易,并允许开发人员使用他们偏好的语言来利用这些平台。
Apache Arrow 现在在许多编程语言中都有实现,包括 C、C++、C#、Go、Java、JavaScript、Julia、MATLAB、Python、R、Ruby 和 Rust。
Arrow Memory Model 内存模型
在 Arrow 的网站上详细描述了这一内存模型,但实际上每一个列都是由单个向量表示,其中包含原始数据,以及表示空值的独立向量和可变宽度类型的原始数据偏移量。
Inter-Process Communication (IPC) 程间通讯
正如之前所提,可以通过指针在进程和进程之间传递数据。然而,接收进程需要知道如何解析这些数据,因此交换元数据 (如 schema 结构信息) 定义了 IPC 的数据格式。Arrow 使用 Google Flatbuffers 进行元数据格式定义。
Compute Kernels 计算内核
Apache Arrow 的范围已经扩展到提供计算库来评估数据表达式。Java、C++、C、Python、Ruby、Go、Rust 和 JavaScript 实现等都包含了用于在 Arrow 内存块上执行计算的计算库。
由于这本书主要涉及 Java 实现,值得指出的是,Dremio 最近贡献了 Gandiva 项目,这是一个 Java 库,可以将表达式编译为 LLVM,并支持 SIMD。JVM 开发者可以将操作委托给 Gandava 库,并从中获得纯 Java 实现中难以企及的性能提升 。
Arrow Flight Protocol
最近,Arrow 已经定义了一个名为 Flight 的协议,以便在网络上高效地传输 Arrow 数据。Flight 基于 gRPC 和 Google Protocol Buffers.
Flight 协议由以下方法定义了一个 FlightService:
译者注:在阅读下文之前先对 Google Protobuf 和 gRPC 中的 Service、Client Side 接口和 Stream 有所了解。
Handshake
客户端与服务端之间的握手。根据服务器的不同,可能需要握手来决定用于未来操作的 Token。根据验证机制,请求和响应应都是允许多次往返的数据流 (gRPC Stream)。
LightFlights
获取给定特定条件下的可用流列表。大多数 Flight 服务都会公开一个或多个流。这个 API 允许列出可用的流。用户也可以提供一套标准,用于限制通过该接口列出的流的子集。每个 Flight 服务都允许自己定义如何使用标准。
GetFlightInfo
对于给定的 FilgthDescriptor,获取有关 Flight 可以如何被消费的信息。如果接口的使用者已经可以识别要消费的特定 Flight,那这将会是一个非常有用的接口。该接口还允许消费者通过指定的描述符生成 Flight 流。例如:一个 Flight 描述符可能包含待执行的 SQL 语句或序列化的 Python 操作。在这些情况下,之前在 ListFilghts 可用流列表中未提供的流,反而在特定的 Flight 服务定义期间是可用的。
GetSchema
对于给定的 FlightDescriptor,获取 Schema.fbs::Schema 中描述的 Schema。该接口被用于当消费者需要 Flight 流的 Schema 时。与 GetFlightInfo 类似,该接口可以生成一个之前在 ListFlights 可用列表中未列出的新的 Flight。
DoGet
检索与引用 ticket 相关的特定描述符所关联的单个流。Flight 可以由一个或多个数据流组成,其中每个数据流都可以使用单独的 opaque ticket 不透明凭证进行检索,Flight 服务使用该 ticket 管理数据流的集合。
DoPut
将流推送到与特定 Flight 流相关的 Flight 服务。这允许 Flight 服务的客户端上传数据流。根据特定的 Flight 服务,可以允许客户端消费者上传每个描述符的单个流,也可以上传数量不限的流。后者,服务可能会实现一个 "seal" 动作,一旦所有的流被上传,这个动作就可以应用到一个描述符上。
DoExchange
为指定描述符打开双向数据通道。这允许客户端在单个逻辑流中发送和接收任意 Arrow 数据和特定应用程序的元数据。与 DoGet/DoPut 不同的是,这样操作更适合将计算(而非存储)转移到 Flight 服务的客户端。
DoAction
除了可能提供的 ListFlights、GetFlightInfo、DoGet 和 DoPut 操作外,Flight 服务还可以支持任意数量的简单操作。DoAction 允许 Flight 客户端对 Flight 服务执行特定事件。一个事件包括 opaque request 匿名请求和响应对象,这些对象与所执行的事件类型有关。
ListActions
Flight 服务会暴露出所有可用的事件类型及其说明。这可以让不同的 Flight 消费者了解到 Flight 服务所提供的功能。
Arrow Flight SQL
有人提议为 Arrow Flight 添加 SQL 功能。在撰写本报告时 (2021 年 1 月),有一份 C++ 实现的 PR,跟踪 Issue 是 ARROW-14698。
Query Engines 查询引擎
DataFusion
Arrow 的 Rust 实现包含一个名为 DataFusion 的内存查询引擎,该引擎于 2019 年贡献给该项目。该项目正在迅速成熟,并获得了越来越多的关注。例如,InfluxData 正在利用 DataFusion 构建下一代 InfluxDB 内核。
Ballista
Ballista 是一个主要由 Rust 实现、Apache Arrow 支持的的分布式计算平台。它的架构允许其它编程语言 (如 Python、C++ 和 Java) 作为一等公民获得支持,而无需考虑序列化开销。
Ballista 的技术基础如下:
- Apache Arrow 用于内存模型和类型系统
- Apache Arrow Flight 协议,用于在进程间高效传输数据
- Apache Arrow Flight SQL 协议,用于商业智能工具和 JDBC 驱动程序连接 Ballista 集群
- Google Protocol Buffers,用于序列化查询计划、
- Docker 用于打包执行器和用户自定义代码
- Kubernetes 用于部署和管理执行器所在的 docker 容器
Ballista 于 2021 年贡献给 Arrow 项目,目前还不能用于生产,不过它能够以良好的性能运行主流 TPC-H 基准中的许多查询案例。
C++ Query Engine
新增的 C++ 版本查询引擎正在实现中,当下的重点是实现高效计算和数据集 API。
Choosing a Type System 选择一个类型系统
本章节所讨论的源代码可以在 KQuery 项目的 datatypes 模块中找到。
构建查询引擎的第一步是选择一个类型系统来表示查询引擎将要处理的不同类型的数据。有种方法是为查询引擎发明一个专有的类型系统。另一种方法是使用查询引擎所要查询的数据源的类型系统。
如果查询引擎将支持多个数据源(通常是这种情况),那么每所支持的数据源和查询引擎的类型系统之间可能需要进行一些转换,因此使用一个兼容并包的类型系统非常重要。
Row-Based or Columnar? 基于行式还是列式?
一个重要的考察因素就是查询引擎是逐行处理,还是以列格式表示数据。
如今许多的查询引擎都是基于 Volcano Query Planner,其在物理层上的每一步基本都是以行迭代器为规划的。这种模型实现起来很简单,但是在对数十亿数据进行查询的时候,查询每行的开销往往会快速增加。通过对数据进行批量迭代,可以减少这种开销。此外,如果这些批量数据代表的是列数据而不是行数据,那么就可以使用 "矢量化处理",利用 SIMD (单指令多数据) 的又是,用一条 CPU 指令处理一列中的多个值。通过利用 GPU 来并行处理跟大量的数据,这个概念还可以更进一步。
Interoperability 可交互性
另一个考虑的因素是,我们可能希望用多种编程语言访问我们的查询疫情。查询引擎用户通常使用 Python、R 或 Java 等语言。我们可能还想构建 ODBC 或 JDBC 驱动程序,便于构建和集成。
考虑到这些需求,最好能找到一种行业标准来表示列式数据,并在进程之间高效交换这些数据。
我认为 Apache Arrow 提供了一个理想的基础,这一结论可能不出所料。
Type System 类型系统
我们将使用 Apache Arrow 作类型系统的基础。下面的 Arrow 用于表示模式、字段和数据类型。
- Schema 模式为数据源或查询结果提供元数据。模式由一个或多个字段组成
- Field 为模式中的字段提供名称和数据类型,并指定是否允许空值
- FieldVector 为字段提供列式数据存储
- ArrowType 表示数据类型
KQuery 引入了一些额外的类和助手,作为 Apache Arrow 类型系统的抽象。
KQuery 为受支持的 Arrow 数据类型提供了可引用的产量。
object ArrowTypes {
val BooleanType = ArrowType.Bool()
val Int8Type = ArrowType.Int(8, true)
val Int16Type = ArrowType.Int(16, true)
val Int32Type = ArrowType.Int(32, true)
val Int64Type = ArrowType.Int(64, true)
val UInt8Type = ArrowType.Int(8, false)
val UInt16Type = ArrowType.Int(16, false)
val UInt32Type = ArrowType.Int(32, false)
val UInt64Type = ArrowType.Int(64, false)
val FloatType = ArrowType.FloatingPoint(FloatingPointPrecision.SINGLE)
val DoubleType = ArrowType.FloatingPoint(FloatingPointPrecision.DOUBLE)
val StringType = ArrowType.Utf8()
}
KQuery 并没有直接使用 FieldVector,而是引入了一个 ColumnVector 接口作为抽象,以提供更方便的访问方法,从而避免了每注数据类型都使用特定的 FieldVector 实现。
interface ColumnVector {
fun getType(): ArrowType
fun getValue(i: Int) : Any?
fun size(): Int
}
这种抽象也使得标量值的实现称为可能,从而避免了用字面值为列中每个索引重复创建和填入 FieldVector。
class LiteralValueVector(
val arrowType: ArrowType,
val value: Any?,
val size: Int) : ColumnVector {
override fun getType(): ArrowType {
return arrowType
}
override fun getValue(i: Int): Any? {
if (i<0 || i>=size) {
throw IndexOutOfBoundsException()
}
return value
}
override fun size(): Int {
return size
}
}
KQuery 还提供了一个 RecordBatch 来表示批量处理的列式数据。
class RecordBatch(val schema: Schema, val fields: List<ColumnVector>) {
fun rowCount() = fields.first().size()
fun columnCount() = fields.size
/** Access one column by index */
fun field(i: Int): ColumnVector {
return fields[i]
}
}
Data Sources 数据源
本章讨论的源代码可以在 KQuery 项目的 datasource 模块中找到。
如果没有可读取的数据源,查询引擎便无计可施,为此我们希望能够支持多种数据源。因此为查询引擎创建一个可以用来与数据源交互的接口就显得尤为重要。这也允许用户将我们的查询引擎用于他们自定义的数据源。数据源通常是文件或者数据库,当也可以是内存对象。
Data Source Interface 数据源接口
在查询计划过程中,必须要了解数据源的模式 (schema),这样才能验证查询计划,确保所引用的列存在,并且数据类型与用于引用列的表达式兼容。在某些情况下,可能无法获得模式,因为某些数据源没有固定的模式,这种情况通常被称为 schema-less。JSON 文档就是一个无模式数据源的例子。
在执行期间,我们需要能够从数据源中获取数据的能力,并要能够指定将哪些列加载到内存中以提高效率。如果查询不引用列,就没必要将其加载到内存中。
KQuery 数据源接口
interface DataSource {
/** Return the schema for the underlying data source */
fun schema(): Schema
/** Scan the data source, selecting the specified columns */
fun scan(projection: List<String>): Sequence<RecordBatch>
}
Data Source Examples 数据源示例
Comma-Separated Values (CSV)
CSV 文件是每行一个记录的文本文件,字段之间使用逗号分隔,因此称为 “逗号分隔值”。CSV 文件不包含模式信息(除文件第一行的可选列名),尽管可以通过想读取文件来派生出模式。但这可能是一个开销高昂的操作。
JSON
JavaScript Object Notation 格式 (JSON) 是另一种流行的基于文本的文件格式。与 CSV 文件不同,JSON 的文件是结构化的,可以存储复杂的嵌套数据类型。
Parquet
Parquet 的创建是为了提供一种压缩、高效的列式数据表示,它是 Hadoop 生态系统中一种流行的文件格式。Parquet 从一开始就考虑到了复杂的嵌套数据结构,并使用了 Dremel 论文中描述的 record shredding and assembly 算法。
Parquet 文件包含模式信息,数据按 batch 批量存储 (称为 “行组”),其中每个批量数据由列组成。行组可以包含压缩数据,也可以包含可选的元数据,例如每列的最大值和最小值。可以对查询引擎进行优化,以使用该元数据来确定在扫描期间可以跳过行组的时机。
Optimized Row Columnar (Orc)
行优化列 (Orc) 格式类似于 Parquet 格式。数据以列传进行批量储存,称为 “stripes 条纹”。
Logical Plans & Expressions 逻辑计划和表达式
本章讨论的源代码可以在 KQuery 项目的 logical-plan 模块中找到。
一个逻辑计划表示具有已知模式的关系(一组元组)。每个逻辑计划可以由零个或者多个逻辑计划作为输入。对于逻辑计划来说,暴露它的子计划是很方便的,这样以访问者模式就可以对计划进行遍历。
译者注:此处的 Logical Plans 指的是一种可递归的树结构,其继承自 Query Plans。
interface LogicalPlan {
fun schema(): Schema
fun children(): List<LogicalPlan>
}
Printing Logical Plans 打印逻辑计划
能够以人类可读形式打印逻辑计划在调试过程中有着不可或缺的意义。逻辑哦计划通常打印成以子节点索引的层次结构。
我们可以实现一个简单的递归助手函数,用于逻辑计划的格式化输出。
fun format(plan: LogicalPlan, indent: Int = 0): String {
val b = StringBuilder()
0.rangeTo(indent).forEach { b.append("\t") }
b.append(plan.toString()).append("\n")
plan.children().forEach { b.append(format(it, indent+1)) }
return b.toString()
}
下面是使用该方法进行逻辑计划格式化的结果示例:
Projection: #id, #first_name, #last_name, #state, #salary
Filter: #state = 'CO'
Scan: employee.csv; projection=None
Serialization 序列化
有时候需要能够序列化查询计划,以便可以轻松实现在进程之间转移。在早期添加序列化是一个好习惯,对不小心引用了无法序列化的数据结构(例如文件句柄或数据库连接)采取预防措施。
一种方法是采用所实现语言的默认机制来序列化数据结构,以符合 JSON 等格式。例如,在 Java 中可以使用 Jackson,而 Kotlin 有 kotlinx.serialization 库,对于 Rust 有 serde crate。
另一种选择是使用 Avro、Thrift 或 Protocol Buffers 这类与语言无关的序列化格式,然后编写代码实现在这种格式和特定语言之间的转换。
自从本书出版第一版以来,出现了一个名为 "substrait" 的新标准,目的是为关系代数提供跨语言序列化。我对这个项目感到非常兴奋,并预测它将因代表了查询计划和开创许多集成可能性而成为事实标准。例如,可以使用基于 Java 的成熟的规划器,如 Apache Calcite,以 Substrait 格式序列化计划,然后在较低级别的语言(如 C++ 或 Rust)实现的查询引擎中执行该计划。更多信息请访问 https://substrait.io/。
Logical Expressions 逻辑表达式
表达式这一概念是查询计划的基本构建块之一,其可以在运行时对数据进行评估。
下面是查询引擎中常见支持的表达式示例:
| 表达式 | 示例 |
|---|---|
| Literal Value 字面值 | "hello", 12.34 |
| Column Reference 列引用 | user_id, first_name, last_name |
| Math Expression 数学表达式 | salary * state_tax |
| Comparison Expression 比较表达式 | x >= y |
| Boolean Expression 布尔表达式 | birthday = today() AND age >= 21 |
| Arrgregate Expression 聚合表达式 | MIN(salary), MAX(salary), SUM(salary), AVG(salary), COUNT(*) |
| Scalar Function 标量函数 | CONCAT(first_name, " ", last_name) |
| Aliased Expression 别名表达式 | salary * 0.02 AS pay_increase |
当然,所有这些表达式都可以组合起来形成具有深度的嵌套表达式树。表达式求值是递归编程的经典案例。
当我们计划进行查询时,我们需要知道一些关于表达式输出的基本元数据。具体来说,我们需要表达式有一个名称,以便其它表达式可以引用它,并且我们需要知道表达式在求值时将产生得值的数据类型,以便我们可以验证查询计划是否有效。例如,如果我们有一个表达式 a + b,则只有当 a 和 b 都为数字类型的情况下该表达式才有效。
还要注意,表达式的数据类型可以依赖于输入数据。例如,列引用将具有它所引用的列的数据类型,但是比较表达式总是返回布尔值。
interface LogicalExpr {
fun toField(input: LogicalPlan): Field
}
Column Expressions 列式表达式
列式表达式仅表示对指定列的引用。此表达式的元数据是通过查找输入中指定的列,并返回该列的元数据派生的。注意,这里的术语“列”是指输入逻辑计划生成的列,可以表示数据源中的列,也可以表示对其它输入求值表达式的结果。
class Column(val name: String): LogicalExpr {
override fun toField(input: LogicalPlan): Field {
return input.schema().fields.find { it.name == name } ?:
throw SQLException("No column named '$name'")
}
override fun toString(): String {
return "#$name"
}
}
Literal Expression 字面值表达式
我们需要将字面值转化为表达式的能力,以便我们可以编写诸如 salary * 0.05 这类的表达式。
下面是字面字符串表达式的示例:
class LiteralString(val str: String): LogicalExpr {
override fun toField(input: LogicalPlan): Field {
return Field(str, ArrowTypes.StringType)
}
override fun toString(): String {
return "'$str'"
}
}
下面是字面长整型表达式的示例:
class LiteralLong(val n: Long): LogicalExpr {
override fun toField(input: LogicalPlan): Field {
return Field(n.toString(), ArrowTypes.Int64Type)
}
override fun toString(): String {
return n.toString()
}
}
Binary Expressions 二元表达式
二元表达式是仅有两个输入的表达式。我们将实现三种类型的二元表达式:比较表达式、布尔表达式和数学表达式。因为所有这些的字符串表示都是相同的,所以我们可以使用公共基类提供的 toString 方法。变量 'l' 和 'r' 分别代表左右输入。
abstract class BinaryExpr(
val name: String,
val op: String,
val l: LogicalExpr,
val r: LogicalExpr) : LogicalExpr {
override fun toString(): String {
return "$l $op $r"
}
}
比较表达式,例如:= 或 < 比较两个相同类型数据,并返回一个布尔值。我们还需要实现布尔运算符 AND 和 OR,它们也接收两个参数并产生一个布尔结果,因此我们也可以为它们使用一个公共的基类。
abstract class BooleanBinaryExpr(
name: String,
op: String,
l: LogicalExpr,
r: LogicalExpr) : BinaryExpr(name, op, l, r) {
override fun toField(input: LogicalPlan): Field {
return Field(name, ArrowTypes.BooleanType)
}
}
这个基类提供了一种实现具体比较表达式的简明方法。
Comparison Expressions 比较表达式
/** Equality (`=`) comparison */
class Eq(l: LogicalExpr, r: LogicalExpr)
: BooleanBinaryExpr("eq", "=", l, r)
/** Inequality (`!=`) comparison */
class Neq(l: LogicalExpr, r: LogicalExpr)
: BooleanBinaryExpr("neq", "!=", l, r)
/** Greater than (`>`) comparison */
class Gt(l: LogicalExpr, r: LogicalExpr)
: BooleanBinaryExpr("gt", ">", l, r)
/** Greater than or equals (`>=`) comparison */
class GtEq(l: LogicalExpr, r: LogicalExpr)
: BooleanBinaryExpr("gteq", ">=", l, r)
/** Less than (`<`) comparison */
class Lt(l: LogicalExpr, r: LogicalExpr)
: BooleanBinaryExpr("lt", "<", l, r)
/** Less than or equals (`<=`) comparison */
class LtEq(l: LogicalExpr, r: LogicalExpr)
: BooleanBinaryExpr("lteq", "<=", l, r)
Boolean Expressions 布尔表达式
基类还提供了一种实现具体布尔逻辑表达式的简明方法。
/** Logical AND */
class And(l: LogicalExpr, r: LogicalExpr)
: BooleanBinaryExpr("and", "AND", l, r)
/** Logical OR */
class Or(l: LogicalExpr, r: LogicalExpr)
: BooleanBinaryExpr("or", "OR", l, r)
Math Expressions 数学表达式
数学表达式是另一种特异化的二元表达式。数学表达式通常对相同数据类型的值进行操作,并产生相同数据类型的结果。
abstract class MathExpr(
name: String,
op: String,
l: LogicalExpr,
r: LogicalExpr) : BinaryExpr(name, op, l, r) {
override fun toField(input: LogicalPlan): Field {
return Field("mult", l.toField(input).dataType)
}
}
class Add(l: LogicalExpr, r: LogicalExpr) : MathExpr("add", "+", l, r)
class Subtract(l: LogicalExpr, r: LogicalExpr) : MathExpr("subtract", "-", l, r)
class Multiply(l: LogicalExpr, r: LogicalExpr) : MathExpr("mult", "*", l, r)
class Divide(l: LogicalExpr, r: LogicalExpr) : MathExpr("div", "/", l, r)
class Modulus(l: LogicalExpr, r: LogicalExpr) : MathExpr("mod", "%", l, r)
Aggregate Expressions 聚合表达式
聚合表达式对输入表达式执行诸如 MIN、MAX、COUNT、SUM 或 AVG 等聚合函数。
abstract class AggregateExpr(
val name: String,
val expr: LogicalExpr) : LogicalExpr {
override fun toField(input: LogicalPlan): Field {
return Field(name, expr.toField(input).dataType)
}
override fun toString(): String {
return "$name($expr)"
}
}
对于聚合表达式而言,若聚合数据类型与输入类型相同,我们可以简单地扩展这个基类。
class Sum(input: LogicalExpr) : AggregateExpr("SUM", input)
class Min(input: LogicalExpr) : AggregateExpr("MIN", input)
class Max(input: LogicalExpr) : AggregateExpr("MAX", input)
class Avg(input: LogicalExpr) : AggregateExpr("AVG", input)
对于聚合表达式而言,若数据类型并不依赖于输入数据类型,我们需要重写 toField 方法。例如:"COUNT" 聚合表达式总是生成一个整数,而不管被计数的值的数据类型是什么。
class Count(input: LogicalExpr) : AggregateExpr("COUNT", input) {
override fun toField(input: LogicalPlan): Field {
return Field("COUNT", ArrowTypes.Int32Type)
}
override fun toString(): String {
return "COUNT($expr)"
}
}
Logicasl Plans 逻辑计划
有了逻辑表达式,我们现在可以为查询引擎将要支持的逻辑计划实现各种转换。
Scan 扫描
Scan 扫描逻辑计划表示按可选 projection 映射从 DataSource 数据源中获取数据。Scan 是查询引擎中唯一没有其它逻辑计划作为输入的逻辑计划,它是查询树中的叶节点。
class Scan(
val path: String,
val dataSource: DataSource,
val projection: List<String>): LogicalPlan {
val schema = deriveSchema()
override fun schema(): Schema {
return schema
}
private fun deriveSchema() : Schema {
val schema = dataSource.schema()
if (projection.isEmpty()) {
return schema
} else {
return schema.select(projection)
}
}
override fun children(): List<LogicalPlan> {
return listOf()
}
override fun toString(): String {
return if (projection.isEmpty()) {
"Scan: $path; projection=None"
} else {
"Scan: $path; projection=$projection"
}
}
}
Projection 映射
Projection 映射逻辑计划将映射应用于其输入。映射是带输入数据进行求值的表达式的列表。有时,它是一个简单的列的列表,例如,SELECT a, b, c FROM foo。但它也可以包含支持的任何其它类型的表达式。一个更为复杂的例子是 SELECT (CAST(A AS float) * 3.141592) AS my_float FROM foo。
class Projection(
val input: LogicalPlan,
val expr: List<LogicalExpr>): LogicalPlan {
override fun schema(): Schema {
return Schema(expr.map { it.toField(input) })
}
override fun children(): List<LogicalPlan> {
return listOf(input)
}
override fun toString(): String {
return "Projection: ${ expr.map {
it.toString() }.joinToString(", ")
}"
}
}
Selection (also known as Filter) 选择(也称之为过滤器)
Selection 选择逻辑计划应用过滤器表达式来确定应该在其输出中选择(包括)哪些行。这是由 SQL 中的 WHERE 子句来表示的。一个简单的例子是 SELECT * FROM foo WHERE A > 5。过滤器表达式需要求值结果为布尔类型。
class Selection(
val input: LogicalPlan,
val expr: Expr): LogicalPlan {
override fun schema(): Schema {
// selection does not change the schema of the input
return input.schema()
}
override fun children(): List<LogicalPlan> {
return listOf(input)
}
override fun toString(): String {
return "Filter: $expr"
}
}
Aggregate 聚合
Aggregate 聚合逻辑计划比Projection 映射、Selection 选择或Scan 扫描要复杂得多。它对底层数据进行聚合,例如计算最小值、最大值、平均值和数据求和。聚合通常按照其它列(或表达式)进行分组。一个简单的例子:SELECT job_title, AVG(salary) FROM employee GROUP BY job_title (按照职位求平均薪水)。
class Aggregate(
val input: LogicalPlan,
val groupExpr: List<LogicalExpr>,
val aggregateExpr: List<AggregateExpr>) : LogicalPlan {
override fun schema(): Schema {
return Schema(groupExpr.map { it.toField(input) } +
aggregateExpr.map { it.toField(input) })
}
override fun children(): List<LogicalPlan> {
return listOf(input)
}
override fun toString(): String {
return "Aggregate: groupExpr=$groupExpr, aggregateExpr=$aggregateExpr"
}
}
注意,在此实现中,聚合计划的输出使用分组和聚合表达式进行组织。通常需要将聚合逻辑计划封装在映射中,以便按照原始查询中请求的顺序返回列。
Building Logical Plans 构建逻辑计划
本章讨论的源代码可以在 KQuery 项目的 logical-plan 模块中找到。
Building Logical Plans The Hard Way 以复杂方式构建逻辑计划
既然我们已经为逻辑计划的子集定义了类,那么我们就可以以编程方式区组合它们了。
针对 CSV 文件中包含的列:id、first_name、last_name、state、job_title、salary,这里有一些具体的代码,用于构建查询计划 SELECT * FROM emplopyee WHERE state = 'co'。
// create a plan to represent the data source
val csv = CsvDataSource("employee.csv")
// create a plan to represent the scan of the data source (FROM)
val scan = Scan("employee", csv, listOf())
// create a plan to represent the selection (WHERE)
val filterExpr = Eq(Column("state"), LiteralString("CO"))
val selection = Selection(scan, filterExpr)
// create a plan to represent the projection (SELECT)
val projectionList = listOf(Column("id"),
Column("first_name"),
Column("last_name"),
Column("state"),
Column("salary"))
val plan = Projection(selection, projectionList)
// print the plan
println(format(plan))
将计划打印输出如下:
Projection: #id, #first_name, #last_name, #state, #salary
Filter: #state = 'CO'
Scan: employee; projection=None
同样的代码也可以像这样写得更加简洁:
val plan = Projection(
Selection(
Scan("employee", CsvDataSource("employee.csv"), listOf()),
Eq(Column(3), LiteralString("CO"))
),
listOf(Column("id"),
Column("first_name"),
Column("last_name"),
Column("state"),
Column("salary"))
)
println(format(plan))
虽然这样更加简洁,但也更难解释,所以最好能有一种更优雅的方式来创建逻辑计划。这就是 DataFrame 接口方便的地方。
Building Logical Plans using DataFrames 使用 DataFrames 接口构建逻辑计划
通过实现 DataFrame 风格的 API 让我们以一种更加用户友好的方式构建逻辑查询计划。DataFrame 只是围绕逻辑查询计划的一个抽象,并具有执行转换和事件的方法。它与 fluent-style 构建器的 API 非常相似。
这里是 DataFrame 接口的最小实现,它允许我们将 proijections 映射和 selections 选择应用于一个现有的 DataFrame。
interface DataFrame {
/** Apply a projection */
fun project(expr: List<LogicalExpr>): DataFrame
/** Apply a filter */
fun filter(expr: LogicalExpr): DataFrame
/** Aggregate */
fun aggregate(groupBy: List<LogicalExpr>,
aggregateExpr: List<AggregateExpr>): DataFrame
/** Returns the schema of the data that will be produced by this DataFrame. */
fun schema(): Schema
/** Get the logical plan */
fun logicalPlan() : LogicalPlan
}
如下是该接口的实现:
class DataFrameImpl(private val plan: LogicalPlan) : DataFrame {
override fun project(expr: List<LogicalExpr>): DataFrame {
return DataFrameImpl(Projection(plan, expr))
}
override fun filter(expr: LogicalExpr): DataFrame {
return DataFrameImpl(Selection(plan, expr))
}
override fun aggregate(groupBy: List<LogicalExpr>,
aggregateExpr: List<AggregateExpr>): DataFrame {
return DataFrameImpl(Aggregate(plan, groupBy, aggregateExpr))
}
override fun schema(): Schema {
return plan.schema()
}
override fun logicalPlan(): LogicalPlan {
return plan
}
}
在我们应用映射或选择之前,我们需要一种方式来表示底层数据源的初始 DataFrame。这通常通过执行上下文来获得。
译者注:即如何从数据源中获取基础数据
如下是执行上下文的一个基础实现,稍后我们将对其进行增强扩展。
class ExecutionContext {
fun csv(filename: String): DataFrame {
return DataFrameImpl(Scan(filename, CsvDataSource(filename), listOf()))
}
fun parquet(filename: String): DataFrame {
return DataFrameImpl(Scan(filename, ParquetDataSource(filename), listOf()))
}
}
有了这项基础工作,我们现在可以使用上下文和 DataFrame API 创建一个逻辑查询计划。
val ctx = ExecutionContext()
val plan = ctx.csv("employee.csv")
.filter(Eq(Column("state"), LiteralString("CO")))
.select(listOf(Column("id"),
Column("first_name"),
Column("last_name"),
Column("state"),
Column("salary")))
这样会更加清晰和只管,但是我们还可以再进一步添加一些简便的方法,使之更易于理解。这是 Kotlin 特有的,不过其它语言也有类似的概念。
infix fun LogicalExpr.eq(rhs: LogicalExpr): LogicalExpr { return Eq(this, rhs) }
infix fun LogicalExpr.neq(rhs: LogicalExpr): LogicalExpr { return Neq(this, rhs) }
infix fun LogicalExpr.gt(rhs: LogicalExpr): LogicalExpr { return Gt(this, rhs) }
infix fun LogicalExpr.gteq(rhs: LogicalExpr): LogicalExpr { return GtEq(this, rhs) }
infix fun LogicalExpr.lt(rhs: LogicalExpr): LogicalExpr { return Lt(this, rhs) }
infix fun LogicalExpr.lteq(rhs: LogicalExpr): LogicalExpr { return LtEq(this, rhs) }
有了这些简便的方法,我们现在可以编写表达式代码来构建逻辑查询计划。
val df = ctx.csv(employeeCsv)
.filter(col("state") eq lit("CO"))
.select(listOf(
col("id"),
col("first_name"),
col("last_name"),
col("salary"),
(col("salary") mult lit(0.1)) alias "bonus"))
.filter(col("bonus") gt lit(1000))
Physical Plan & Expressions 物理计划和表达式
本章讨论的源代码可以在 KQuery 项目的 physical-plan 模块中找到。
译者注:此处未找到适合
Physical的表意词,大意指软件逻辑和硬件调度优化设计进行分离。
在第五章中定义的逻辑计划指定了该怎么实现,但是没有阐述如何实现。并且尽管将逻辑和物理计划结合起来可以降低开发复杂度,但将二者分开仍就是一个很好的实践。
将逻辑和物理计划分开的一个原因是,有事执行特定的操作可能有多种方式,这也意味着逻辑计划和物理计划之间存在着一对多的关系。
例如,当进程执行与分布式执行,或者 CPU 执行与 GPU 执行之间可能存在单独的物理计划。
此外,诸如 Aggregate 聚合和 Join 连接之类的操作可以按性能来权衡各种算法进行实现。当聚合数据已经按照 gouping keys 分组键进行排序的时候,使用 Group Aggregate(也称之为软聚合)是行之有效的,它一次只需要保存一组分组键的状态,并可以在一组分组键结束的时候立即发出结果。而如果是未经排序的数据,则往往使用 Hash 聚合。Hash 聚合通过对键进行分组来维护累加器的 HashMap。
连接的算法实现则更为宽泛,包括嵌套循环连接、排序合并连接和 Hash 连接。
物理计划返回 RecordBatch 类型的迭代器。
interface PhysicalPlan {
fun schema(): Schema
fun execute(): Sequence<RecordBatch>
fun children(): List<PhysicalPlan>
}
Physical Expressions 物理表达式
我们已经定义了在逻辑计划中应用的逻辑表达式,但是我们现在需要实现包含代码的物理表达式类,以计算运行时的表达式。
每个逻辑表达式可以由多个物理表达式实现。例如,对将两个数字相加的逻辑表达式 AddExpr,我们可以分别由 CPU 和 GPU 进行实现。查询规划器可以根据运行代码所在服务器的硬件能力选择使用哪个实现。
物理表达式针对 RecordBatch 进行求值,并且求值结果为 ColumnVector。
这是我们将用来表示物理表达式的接口:
interface Expression {
fun evaluate(input: RecordBatch): ColumnVector
}
Column Expressions 列表达式
列表达式只需要对正在处理的 RecordBatch 进行简单的计算并返回 ColumnVector 引用。逻辑表达式中按名称引用 Column,这对于编写查询语句的用户来说是非常友好的,但是对于物理表达式而言,我们希望避免每次计算表达式都要花费在名称查找上的开销,因此将它改为按序号引用 (val i: Int)。
class ColumnExpression(val i: Int) : Expression {
override fun evaluate(input: RecordBatch): ColumnVector {
return input.field(i)
}
override fun toString(): String {
return "#$i"
}
}
Literal Expressions 字面值表达式
物理上实现一个字面值表达式实质上只是简单地将一个字面值包装在类中,并且该类实现了适当的 trait,并为列中每个索引提供相同的值。
译者注:Traits 特征,此概念可参考 Rust 语言,理解为一种抽象接口 interface。
class LiteralValueVector(
val arrowType: ArrowType,
val value: Any?,
val size: Int) : ColumnVector {
override fun getType(): ArrowType {
return arrowType
}
override fun getValue(i: Int): Any? {
if (i<0 || i>=size) {
throw IndexOutOfBoundsException()
}
return value
}
override fun size(): Int {
return size
}
}
有了这个类,我们就可以为每种数据类型的字面值表达式创建物理表达式了。
class LiteralLongExpression(val value: Long) : Expression {
override fun evaluate(input: RecordBatch): ColumnVector {
return LiteralValueVector(ArrowTypes.Int64Type,
value,
input.rowCount())
}
}
class LiteralDoubleExpression(val value: Double) : Expression {
override fun evaluate(input: RecordBatch): ColumnVector {
return LiteralValueVector(ArrowTypes.DoubleType,
value,
input.rowCount())
}
}
class LiteralStringExpression(val value: String) : Expression {
override fun evaluate(input: RecordBatch): ColumnVector {
return LiteralValueVector(ArrowTypes.StringType,
value.toByteArray(),
input.rowCount())
}
}
Binary Expressions 二元表达式
对于二元表达式,我们需要计算左右输入表达式,然后根据这些输入计算特定的二元运算符,这样我们就可以提供一个基类来简化每个运算符的实现。
abstract class BinaryExpression(val l: Expression, val r: Expression) : Expression {
override fun evaluate(input: RecordBatch): ColumnVector {
val ll = l.evaluate(input)
val rr = r.evaluate(input)
assert(ll.size() == rr.size())
if (ll.getType() != rr.getType()) {
throw IllegalStateException(
"Binary expression operands do not have the same type: " +
"${ll.getType()} != ${rr.getType()}")
}
return evaluate(ll, rr)
}
abstract fun evaluate(l: ColumnVector, r: ColumnVector) : ColumnVector
}
Comparison Expressions 比较表达式
比较表达式只是比较两个输入列中的所有值,并产生一个结果的新列(位向量)。
这里有一个等价运算符的例子:
class EqExpression(l: Expression,
r: Expression): BooleanExpression(l,r) {
override fun evaluate(l: Any?, r: Any?, arrowType: ArrowType) : Boolean {
return when (arrowType) {
ArrowTypes.Int8Type -> (l as Byte) == (r as Byte)
ArrowTypes.Int16Type -> (l as Short) == (r as Short)
ArrowTypes.Int32Type -> (l as Int) == (r as Int)
ArrowTypes.Int64Type -> (l as Long) == (r as Long)
ArrowTypes.FloatType -> (l as Float) == (r as Float)
ArrowTypes.DoubleType -> (l as Double) == (r as Double)
ArrowTypes.StringType -> toString(l) == toString(r)
else -> throw IllegalStateException(
"Unsupported data type in comparison expression: $arrowType")
}
}
}
Math Expressions数学表达式
数学表达式的实现与比较表达式的代码非常类似。一个基类可以用于所有数学表达式。
abstract class MathExpression(l: Expression,
r: Expression): BinaryExpression(l,r) {
override fun evaluate(l: ColumnVector, r: ColumnVector): ColumnVector {
val fieldVector = FieldVectorFactory.create(l.getType(), l.size())
val builder = ArrowVectorBuilder(fieldVector)
(0 until l.size()).forEach {
val value = evaluate(l.getValue(it), r.getValue(it), l.getType())
builder.set(it, value)
}
builder.setValueCount(l.size())
return builder.build()
}
abstract fun evaluate(l: Any?, r: Any?, arrowType: ArrowType) : Any?
}
下面是扩展此基类的一个特定数学表达式示例:
class AddExpression(l: Expression,
r: Expression): MathExpression(l,r) {
override fun evaluate(l: Any?, r: Any?, arrowType: ArrowType) : Any? {
return when (arrowType) {
ArrowTypes.Int8Type -> (l as Byte) + (r as Byte)
ArrowTypes.Int16Type -> (l as Short) + (r as Short)
ArrowTypes.Int32Type -> (l as Int) + (r as Int)
ArrowTypes.Int64Type -> (l as Long) + (r as Long)
ArrowTypes.FloatType -> (l as Float) + (r as Float)
ArrowTypes.DoubleType -> (l as Double) + (r as Double)
else -> throw IllegalStateException(
"Unsupported data type in math expression: $arrowType")
}
}
override fun toString(): String {
return "$l+$r"
}
}
Aggregate Expressions 聚合表达式
到目前为止,我们看到的表达式都是通过每个 batch 中的一个或多个输入列产生一个输出列。而聚合表达式的情况则更为复杂,因为它们跨多个批量记录数据进行聚合,然后产生一个最终值,因此我们需要引入 accumulator 累加器的概念,并且每个聚合表达式的物理表示需要知道如何为查询引擎传入输入数据的累加器。
下面是表示聚合表达式和累加器的主要接口:
interface AggregateExpression {
fun inputExpression(): Expression
fun createAccumulator(): Accumulator
}
interface Accumulator {
fun accumulate(value: Any?)
fun finalValue(): Any?
}
Max 聚合表达式的实现将生成一个特定的 MaxAccumulator。
class MaxExpression(private val expr: Expression) : AggregateExpression {
override fun inputExpression(): Expression {
return expr
}
override fun createAccumulator(): Accumulator {
return MaxAccumulator()
}
override fun toString(): String {
return "MAX($expr)"
}
}
下面是 MaxAccumulator 的一个示例实现:
class MaxAccumulator : Accumulator {
var value: Any? = null
override fun accumulate(value: Any?) {
if (value != null) {
if (this.value == null) {
this.value = value
} else {
val isMax = when (value) {
is Byte -> value > this.value as Byte
is Short -> value > this.value as Short
is Int -> value > this.value as Int
is Long -> value > this.value as Long
is Float -> value > this.value as Float
is Double -> value > this.value as Double
is String -> value > this.value as String
else -> throw UnsupportedOperationException(
"MAX is not implemented for data type: ${value.javaClass.name}")
}
if (isMax) {
this.value = value
}
}
}
}
override fun finalValue(): Any? {
return value
}
}
Physical Plans 物理计划
有了物理表达式,我们现在可以为查询引擎将要支持的各种转换实现物理计划。
Scan 扫描
Scan 扫描执行计划只需要委托给数据源,并传入映射来限制要加载到内存中的列数量。不执行任何附加逻辑。
class ScanExec(val ds: DataSource, val projection: List<String>) : PhysicalPlan {
override fun schema(): Schema {
return ds.schema().select(projection)
}
override fun children(): List<PhysicalPlan> {
// Scan is a leaf node and has no child plans
return listOf()
}
override fun execute(): Sequence<RecordBatch> {
return ds.scan(projection);
}
override fun toString(): String {
return "ScanExec: schema=${schema()}, projection=$projection"
}
}
Projection 映射
Projection 映射执行计划只需要根据输入的列计算映射表达式,然后生成包含派生列的批量记录。注意,对于按名称引用现有列的映射表达式,派生列只是一个只想输入列的指针或引用,因此不会复制底层数据值。
class ProjectionExec(
val input: PhysicalPlan,
val schema: Schema,
val expr: List<Expression>) : PhysicalPlan {
override fun schema(): Schema {
return schema
}
override fun children(): List<PhysicalPlan> {
return listOf(input)
}
override fun execute(): Sequence<RecordBatch> {
return input.execute().map { batch ->
val columns = expr.map { it.evaluate(batch) }
RecordBatch(schema, columns)
}
}
override fun toString(): String {
return "ProjectionExec: $expr"
}
}
Selection (as known as Filter) 选择(也称之为过滤器)
Selection 选择执行计划是第一个重要的计划,因为它有具有条件逻辑,可以确定输入批量记录中的哪些行应该被包含在输出批量数据中。
对于每个输入批量数据,过滤器表达式会计算并返回一个位向量,其中包含表示表达式布尔结果的位,每行对应一位。然后使用该位向量过滤输入列以产生新的输出列。这是一个简单实现,可以针对维向量包含位为全 1 或全 0 的情况进行优化,以避免将无关数据复制到新向量所产生的额外开销。
译者注:Apache Arrow 的 Validity Bitmap Buffer 设计思想的简化实现。
class SelectionExec(
val input: PhysicalPlan,
val expr: Expression) : PhysicalPlan {
override fun schema(): Schema {
return input.schema()
}
override fun children(): List<PhysicalPlan> {
return listOf(input)
}
override fun execute(): Sequence<RecordBatch> {
val input = input.execute()
return input.map { batch ->
val result = (expr.evaluate(batch) as ArrowFieldVector).field as BitVector
val schema = batch.schema
val columnCount = batch.schema.fields.size
val filteredFields = (0 until columnCount).map {
filter(batch.field(it), result)
}
val fields = filteredFields.map { ArrowFieldVector(it) }
RecordBatch(schema, fields)
}
private fun filter(v: ColumnVector, selection: BitVector) : FieldVector {
val filteredVector = VarCharVector("v", RootAllocator(Long.MAX_VALUE))
filteredVector.allocateNew()
val builder = ArrowVectorBuilder(filteredVector)
var count = 0
(0 until selection.valueCount).forEach {
if (selection.get(it) == 1) {
builder.set(count, v.getValue(it))
count++
}
}
filteredVector.valueCount = count
return filteredVector
}
}
Hash Aggregate Hash 聚合
Hash 聚合计划比之前的计划要复杂得多,因为它必须处理所有输入批量数据,维护累加器的 HashMap,并为正在处理的没一行数据更新累加器。组以后,使用累加器的结果在末尾创建一个批量数据记录,其中包含了聚合查询的结果。
class HashAggregateExec(
val input: PhysicalPlan,
val groupExpr: List<Expression>,
val aggregateExpr: List<AggregateExpression>,
val schema: Schema
) : PhysicalPlan {
override fun schema(): Schema {
return schema
}
override fun children(): List<PhysicalPlan> {
return listOf(input)
}
override fun toString(): String {
return "HashAggregateExec: groupExpr=$groupExpr, aggrExpr=$aggregateExpr"
}
override fun execute(): Sequence<RecordBatch> {
val map = HashMap<List<Any?>, List<Accumulator>>()
// for each batch from the input executor
input.execute().iterator().forEach { batch ->
// evaluate the grouping expressions
val groupKeys = groupExpr.map { it.evaluate(batch) }
// evaluate the expressions that are inputs to the aggregate functions
val aggrInputValues = aggregateExpr.map {
it.inputExpression().evaluate(batch)
}
// for each row in the batch
(0 until batch.rowCount()).forEach { rowIndex ->
// create the key for the hash map
val rowKey =
groupKeys.map {
val value = it.getValue(rowIndex)
when (value) {
is ByteArray -> String(value)
else -> value
}
}
// println(rowKey)
// get or create accumulators for this grouping key
val accumulators = map.getOrPut(rowKey) { aggregateExpr.map { it.createAccumulator() } }
// perform accumulation
accumulators.withIndex().forEach { accum ->
val value = aggrInputValues[accum.index].getValue(rowIndex)
accum.value.accumulate(value)
}
}
}
// create result batch containing final aggregate values
val root = VectorSchemaRoot.create(schema.toArrow(), RootAllocator(Long.MAX_VALUE))
root.allocateNew()
root.rowCount = map.size
val builders = root.fieldVectors.map { ArrowVectorBuilder(it) }
map.entries.withIndex().forEach { entry ->
val rowIndex = entry.index
val groupingKey = entry.value.key
val accumulators = entry.value.value
groupExpr.indices.forEach { builders[it].set(rowIndex, groupingKey[it]) }
aggregateExpr.indices.forEach {
builders[groupExpr.size + it].set(rowIndex, accumulators[it].finalValue())
}
}
val outputBatch = RecordBatch(schema, root.fieldVectors.map { ArrowFieldVector(it) })
// println("HashAggregateExec output:\n${outputBatch.toCSV()}")
return listOf(outputBatch).asSequence()
}
}
Joins 连接
顾名思义,Join 运算符用于连接两个相关行。有许多不同类型的连接,伴随着不同的语义。
[INNER] JOIN: 这是最常用的连接类型,它创建了一个包含左右输入行的新关系。如果连接表达式只包含左右输入列之间的等值比较,则这种连接被称为 "equi-join 等值连接"。例如:SELECT * FROM customer JOIN orders ON customer.id = order.customer_id。LEFT [OUTER] JOIN: 左外连接产生的行包含来自左输入的所有值,以及来自右输入的可选行。若右侧没有匹配的结果,则为右侧列生成空值。RIGHT [OUTER] JOIN: 与左连接操作相反。从右边开始的所有行和左边开始的可用行一起返回。SEMI JOIN: 半连接类似于左连接,但它只返回左输入中与右输入匹配的行。右输入没有数据返回。并不是所有的 SQL 实现都显式地支持半连接,它们通常被写成子查询语句。例如:FROM foo WHERE EXISTS (SELECT * FROM bar WHERE foo.id = bar.id)。ANTI JOIN: 反连接与半连接相反。它只返回与右输入匹配的左输入中的行。例如:SELECT id FROM foo WHERE NOT EXISTS (SELECT * FROM bar WHERE foo.id = bar.id)。CROSS JOIN: 交叉连接返回来自左右输入的所有可能的组合行,如果左输入包含 100 行,右输入包含 200 行,则将返回 20,000 行。这被称为笛卡尔积。
KQuery 还没有实现连接操作符。
Subqueries 子查询
子查询是查询中的查询。它们可以相关也可以非相关(取决于是否涉及到其它关系的连接)。当子查询返回单个值时,它被称为标量子查询。
Scalar subqueries 标量子查询
标量子查询返回单个值,可以在许多可以使用字面值的 SQL 表达式中使用。
下面是一个相关标量子查询的示例:
SELECT id, name, (SELECT count(*) FROM orders WHERE customer_id = customer.id) AS num_orders FROM customers;
下面是一个非相关标量子查询的示例:
SELECT * FROM orders WHERE total > (SELECT avg(total) FROM sales WHERE customer_state = 'CA');
相关子查询在执行之前被转换为连接(这将在第 10 章中解释)。
不相关的查询可以单独执行,结果值可以替换到顶级查询中。
EXISTS 和 IN 子查询
EXISTS 和 IN 表达式(以及它们的否定形式 NOT EXISTS 和 NOT IN)可用于创建半连接和反连接。
如下是一个半连接的示例,它从子查询返回匹配行的左关联 (foo) 中选择所有行。
SELECT id FROM foo WHERE EXISTS (SELECT * FROM bar WHERE foo.id = bar.id);
关联子查询通常在逻辑计划优化期间转换为连接(这将在第 10 章中解释)。
KQuery 也还没有实现子查询。
Creating Physical Plans 创建物理计划
物理计划就绪后,下一步是构建一个查询规划器,以便从逻辑计划中创建物理计划,这将在下一章中介绍。
Query Planner 查询规划器
本章讨论的源代码可以在 KQuery 项目的 query-planner 模块中找到。
我们已经定义了逻辑和物理查询计划,现在我们需要一个可以将逻辑计划转换为物理计划的查询规划器。
查询规划器可以根据配置选项或者目标平台的硬件功能选择不同的物理计划。例如,查询可以在 CPU 或 GPU 上执行,也可以在单个节点上执行,或者分布在集群中。
Translating Logical Expressions 翻译逻辑表达式
第一步是定义一个递归地将逻辑表达式翻译成物理表达式的方法。下面地代码示例演示了一个基于 switch 语句的实现,并展示了如何翻译一个二元表达式(它有两个输入表达式),从而使代码递归回到同一个方法来翻译这些输入。这种方法遍历整个逻辑表达式树并创建相应的物理表达式树。
fun createPhysicalExpr(expr: LogicalExpr,
input: LogicalPlan): PhysicalExpr = when (expr) {
is ColumnIndex -> ColumnExpression(expr.i)
is LiteralString -> LiteralStringExpression(expr.str)
is BinaryExpr -> {
val l = createPhysicalExpr(expr.l, input)
val r = createPhysicalExpr(expr.r, input)
...
}
...
}
下面几节将解释每种类型表达式的实现。
Column Expressions 列表达式
逻辑列表达式按名称引用列,但物理表达式使用列索引以提高性能,因此在查询规划器需要执行从列名到列索引的转换,并在列名无效时抛出异常。
下面这个简化的示例按第一个列名进行查找,而并没有监测是否有多个匹配列,这应该是个错误的条件。
is Column -> {
val i = input.schema().fields.indexOfFirst { it.name == expr.name }
if (i == -1) {
throw SQLException("No column named '${expr.name}'")
}
ColumnExpression(i)
Literal Expressions 字面表达式
字面值的物理表达式是非常直观的,并且从逻辑到物理表达式的映射也很简单,因为我们只需要拷贝字面值即可。
is LiteralLong -> LiteralLongExpression(expr.n)
is LiteralDouble -> LiteralDoubleExpression(expr.n)
is LiteralString -> LiteralStringExpression(expr.str)
Binary Expressions 二元表达式
要为二元表达式创建物理表达式,我们首先需要为左右输入创建物理表达式,然后我们再创建特定的物理表达式。
is BinaryExpr -> {
val l = createPhysicalExpr(expr.l, input)
val r = createPhysicalExpr(expr.r, input)
when (expr) {
// comparision
is Eq -> EqExpression(l, r)
is Neq -> NeqExpression(l, r)
is Gt -> GtExpression(l, r)
is GtEq -> GtEqExpression(l, r)
is Lt -> LtExpression(l, r)
is LtEq -> LtEqExpression(l, r)
// boolean
is And -> AndExpression(l, r)
is Or -> OrExpression(l, r)
// math
is Add -> AddExpression(l, r)
is Subtract -> SubtractExpression(l, r)
is Multiply -> MultiplyExpression(l, r)
is Divide -> DivideExpression(l, r)
else -> throw IllegalStateException(
"Unsupported binary expression: $expr")
}
}
Translating Logical Plans 翻译逻辑计划
我们需要实现一个递归方法以遍历逻辑计划树,并将其转换为物理计划树,使用与去前面转换表达式相同的模式。
fun createPhysicalPlan(plan: LogicalPlan) : PhysicalPlan {
return when (plan) {
is Scan -> ...
is Selection -> ...
...
}
Scan 扫描
翻译 Scan 扫描计划只需要复制数据源引用和逻辑计划的映射。
is Scan -> ScanExec(plan.dataSource, plan.projection)
Projection 映射
翻译一个映射有两步。首先,我们需要为映射的输入创建一个物理计划,然后我们需要将映射的逻辑表达式转换为物理表达式。
is Projection -> {
val input = createPhysicalPlan(plan.input)
val projectionExpr = plan.expr.map { createPhysicalExpr(it, plan.input) }
val projectionSchema = Schema(plan.expr.map { it.toField(plan.input) })
ProjectionExec(input, projectionSchema, projectionExpr)
}
Selection (also known as Filter) 选择(也称之为过滤器)
查询计划中 Selection 选择的翻译步骤与 Projection 映射非常相似。
is Selection -> {
val input = createPhysicalPlan(plan.input)
val filterExpr = createPhysicalExpr(plan.expr, plan.input)
SelectionExec(input, filterExpr)
}
Aggregate 聚合
聚合查询的查询规划步骤包括计算可选分组键的表达式和聚合函数的输入表达式,然后创建物理聚合表达式。
is Aggregate -> {
val input = createPhysicalPlan(plan.input)
val groupExpr = plan.groupExpr.map { createPhysicalExpr(it, plan.input) }
val aggregateExpr = plan.aggregateExpr.map {
when (it) {
is Max -> MaxExpression(createPhysicalExpr(it.expr, plan.input))
is Min -> MinExpression(createPhysicalExpr(it.expr, plan.input))
is Sum -> SumExpression(createPhysicalExpr(it.expr, plan.input))
else -> throw java.lang.IllegalStateException(
"Unsupported aggregate function: $it")
}
}
HashAggregateExec(input, groupExpr, aggregateExpr, plan.schema())
}
Query Optimizations 请求优化器
本章讨论的源代码可以在 KQuery 项目的 optimizer 模块中找到。
我们现在有了功能性查询计划,但是我们有赖于终端用户能够以一种有效的方式构造计划。例如,我们希望用户在构建计划的时候能够尽早的使用过滤器,特别是在连接操作之前,因为这样可以限制需要处理的数据量。
是时候来实现一个简单的基于规则的优化器了,它可以重新安排查询计划以提高其效率。
一旦我们在第 11 章中开始支持 SQL,这将变得更加重要,因为 SQL 语言只定义查询应该如何工作,并不总是允许用户去指定运算符和表达式的求值顺序。
Rule-Based Optimizations 基于规则的优化器
基于规则进行优化是一种简单而实用的方法。尽管基于规则的优化器也可以应用于物理计划,但是这些优化器通常在创建物理计划之前针对逻辑计划执行。
优化器的工作方式是使用访问者模式遍历逻辑计划,创建计划中每个步骤的副本并应用必要的修改。这事一种比在执行计划时视图改变状态要简单得多的涉及,并且倾向于不可变状态的函数式编程风格。
我们将会使用下面这些接口来表示优化器规则。
interface OptimizerRule {
fun optimize(plan: LogicalPlan) : LogicalPlan
}
现在,我们将研究大多数查询引擎实施的一些常见的优化规则。
Projection Push-Down 映射下推
译者注:如根据表达式自动提前构建所需的映射关联表。
映射下推的目标是在从磁盘读取数据之后和其它查询阶段之前尽快过滤掉列数据,以减少各操作之间保存在内存中的数据量(并且在分布式查询的情况下可能通过网络传输)。
为了知道查询中引用了哪些列,我们必须编写递归代码以检查表达式并构建列数据列表。
fun extractColumns(expr: List<LogicalExpr>,
input: LogicalPlan,
accum: MutableSet<String>) {
expr.forEach { extractColumns(it, input, accum) }
}
fun extractColumns(expr: LogicalExpr,
input: LogicalPlan,
accum: MutableSet<String>) {
when (expr) {
is ColumnIndex -> accum.add(input.schema().fields[expr.i].name)
is Column -> accum.add(expr.name)
is BinaryExpr -> {
extractColumns(expr.l, input, accum)
extractColumns(expr.r, input, accum)
}
is Alias -> extractColumns(expr.expr, input, accum)
is CastExpr -> extractColumns(expr.expr, input, accum)
is LiteralString -> {}
is LiteralLong -> {}
is LiteralDouble -> {}
else -> throw IllegalStateException(
"extractColumns does not support expression: $expr")
}
}
有了这段实用的代码,我们就可以继续优化器规则了。注意,对于 Projection 映射、Selection 选择和 Aggregate 聚合计划,我们正在构建列名称列表,但是当我们遇到 Scan 扫描(它是一个叶节点)的时候,我们将其替换为查询的列名称列表中的版本。
class ProjectionPushDownRule : OptimizerRule {
override fun optimize(plan: LogicalPlan): LogicalPlan {
return pushDown(plan, mutableSetOf())
}
private fun pushDown(plan: LogicalPlan,
columnNames: MutableSet<String>): LogicalPlan {
return when (plan) {
is Projection -> {
extractColumns(plan.expr, columnNames)
val input = pushDown(plan.input, columnNames)
Projection(input, plan.expr)
}
is Selection -> {
extractColumns(plan.expr, columnNames)
val input = pushDown(plan.input, columnNames)
Selection(input, plan.expr)
}
is Aggregate -> {
extractColumns(plan.groupExpr, columnNames)
extractColumns(plan.aggregateExpr.map { it.inputExpr() }, columnNames)
val input = pushDown(plan.input, columnNames)
Aggregate(input, plan.groupExpr, plan.aggregateExpr)
}
is Scan -> Scan(plan.name, plan.dataSource, columnNames.toList().sorted())
else -> throw new UnsupportedOperationException()
}
}
}
给定的输入逻辑计划为:
Projection: #id, #first_name, #last_name
Filter: #state = 'CO'
Scan: employee; projection=None
此优化器规则将其转换为如下计划:
Projection: #id, #first_name, #last_name
Filter: #state = 'CO'
Scan: employee; projection=[first_name, id, last_name, state]
Predicate Push-Down 谓词下推
谓词下推优化的目的是为了在查询中尽早地过滤掉行,以避免冗余处理。考虑下面的例子,它连接一个 employee 表和 dept 表,然后过滤位于 Colorado 的员工。
Projection: #dept_name, #first_name, #last_name
Filter: #state = 'CO'
Join: #employee.dept_id = #dept.id
Scan: employee; projection=[first_name, id, last_name, state]
Scan: dept; projection=[id, dept_name]
这样查询虽然能够产生正确的结果,但也因为对所有员工数据进行连接导致冗余的开销,而不仅是那些位于 Colorado 的员工。谓词下推规则将把过滤器下推到连接中,如下面的查询计划所示。
Projection: #dept_name, #first_name, #last_name
Join: #employee.dept_id = #dept.id
Filter: #state = 'CO'
Scan: employee; projection=[first_name, id, last_name, state]
Scan: dept; projection=[id, dept_name]
连接现在将只处理员工信息的一个子集,从而达到更好的性能。
Eliminate Common Subexpressions 消除公共子表达式
给定一个查询,例如 SELECT sum(price * qty) as total_price, sum(price * qty * tax_rate) as total_tax FROM ... 我们可以看到表达式 price * qty 出现了两次。我们可以选择重写计划来仅计算一次,而不是执行两次计算。
原计划:
Projection: sum(#price * #qty), sum(#price * #qty * #tax)
Scan: sales
优化后:
Projection: sum(#_price_mult_qty), sum(#_price_mult_qty * #tax)
Projection: #price * #qty as _price_mult_qty
Scan: sales
将相关子查询转换为连接
给定一个查询,例如 SELECT id FROM foo WHERE EXISTS (SELECT * FROM bar WHERE foo.id = bar.id)。一个简单的实现是扫描 foo 中的所有行,然后对 foo 中的每一行在 bar 中执行查找。这样非常低效,因此查询引擎通常将相关子查询转换为连接。这也称为子查询去相关。
上述请求可以重写为 SELECT foo.id FROM foo JOIN bar ON foo.id = bar.id。
Projection: foo.id
LeftSemi Join: foo.id = bar.id
TableScan: foo projection=[id]
TableScan: bar projection=[id]
如果将查询修改为使用 NOT EXISTS 而不是 EXISTS,那么查询计划将使用 LeftAnti 而不是 LeftSemi 进行连接。
Projection: foo.id
LeftAnti Join: foo.id = bar.id
TableScan: foo projection=[id]
TableScan: bar projection=[id]
Cost-Based Optimizations
基于开销的优化是指使用有关基础数据的统计信息来确定执行特定查询的开销,然后通过寻找开销较小的计划来确定最优的执行计划的优化规则。一个很好的实现会根据基础数据表的大小选择要使用的连接算法,或者选择连接表的顺序。
基于开销优化的一个主要缺点是,它们依赖于有关基础数据库的准确性和详细统计信息的可用性。此类统计信息通常包括每列统计信息,例如空值的数量、不同值的数量、最小值和最大值,以及显示列内值分布的直方图。直方图对于能够检测到像 state = 'CA' 这样的谓词可能比 state = 'WY' 产生更多的数据行(California 加利福尼亚州是美国人口最多的州,有 3900 万居民,而 Wyoming 怀俄明州是人口最少的州,居民不到 100 万)。
当使用诸如 Orc 或 Parquet 这类的文件格式时,可以使用其中一些统计信息,但是通常有必要运行一个进程来构建这些统计信息,并且当数据量达到 TB 级,这种做法弊大于利,特别是对于 ad-hoc (临时的、特别的)查询。
Query Execution 查询执行
我们现在可以编写代码来对 CSV 文件执行优化后的查询。
在使用 KQuery 执行查询之前,使用一个可信的替代方案可能很有用,以便我们知道正确的结果应该是什么,并获得一些基线性能指标以进行比较。
Apache Spark Example Apache Spark 示例
本章讨论的源代码可以在 KQuery 的 spark 模块中找到。
首先我们需要创建一个 Spark 上下文。请注意,我们使用单线程执行,以便我们可以相对公平地比较 KQuery 中单线程实现的性能。
val spark = SparkSession.builder()
.master("local[1]")
.getOrCreate()
下一步,我们需要根据上下文将 CSV 文件注册成 DataFrame。
val schema = StructType(Seq(
StructField("VendorID", DataTypes.IntegerType),
StructField("tpep_pickup_datetime", DataTypes.TimestampType),
StructField("tpep_dropoff_datetime", DataTypes.TimestampType),
StructField("passenger_count", DataTypes.IntegerType),
StructField("trip_distance", DataTypes.DoubleType),
StructField("RatecodeID", DataTypes.IntegerType),
StructField("store_and_fwd_flag", DataTypes.StringType),
StructField("PULocationID", DataTypes.IntegerType),
StructField("DOLocationID", DataTypes.IntegerType),
StructField("payment_type", DataTypes.IntegerType),
StructField("fare_amount", DataTypes.DoubleType),
StructField("extra", DataTypes.DoubleType),
StructField("mta_tax", DataTypes.DoubleType),
StructField("tip_amount", DataTypes.DoubleType),
StructField("tolls_amount", DataTypes.DoubleType),
StructField("improvement_surcharge", DataTypes.DoubleType),
StructField("total_amount", DataTypes.DoubleType)
))
val tripdata = spark.read.format("csv")
.option("header", "true")
.schema(schema)
.load("/mnt/nyctaxi/csv/yellow_tripdata_2019-01.csv")
tripdata.createOrReplaceTempView("tripdata")
最后我们可以继续对 DataFrame 执行 SQL。
val start = System.currentTimeMillis()
val df = spark.sql(
"""SELECT passenger_count, MAX(fare_amount)
|FROM tripdata
|GROUP BY passenger_count""".stripMargin)
df.foreach(row => println(row))
val duration = System.currentTimeMillis() - start
println(s"Query took $duration ms")
在我的台式机上执行代码输出结果如下:
[1,623259.86]
[6,262.5]
[3,350.0]
[5,760.0]
[9,92.0]
[4,500.0]
[8,87.0]
[7,78.0]
[2,492.5]
[0,36090.3]
Query took 14418 ms
KQuery Examples KQuery 示例
本章讨论的源代码可以在 KQuery 的 examples 模块中找到。
下面是用 KQuery 实现的等效查询。请注意,这段代码与 Spark 示例不同,因为 KQuery 还没有指定 CSV 文件模式的选项,所以所有数据类型都是字符串。这意味着我们需要向查询计划添加显式强制转换,以将车费金额列转化为数值类型。
val time = measureTimeMillis {
val ctx = ExecutionContext()
val df = ctx.csv("/mnt/nyctaxi/csv/yellow_tripdata_2019-01.csv", 1*1024)
.aggregate(
listOf(col("passenger_count")),
listOf(max(cast(col("fare_amount"), ArrowTypes.FloatType))))
val optimizedPlan = Optimizer().optimize(df.logicalPlan())
val results = ctx.execute(optimizedPlan)
results.forEach { println(it.toCSV()) }
println("Query took $time ms")
这将在我的台式机上产生以下输出:
Schema<passenger_count: Utf8, MAX: FloatingPoint(DOUBLE)>
1,623259.86
2,492.5
3,350.0
4,500.0
5,760.0
6,262.5
7,78.0
8,87.0
9,92.0
0,36090.3
Query took 6740 ms
我们可以看到,结果与 Apache Spark 生成的结果相匹配。我们还看到其在当前输入规模下的性能优化十分可观。由于 Apache Spark 针对 “大数据” 进行了优化,因此在处理更大的数据集时,它的性能很可能会超过 KQuery。
Removing The Query Optimizer 移除查询优化器
让我们一处这些优化,看看它们对性能有多大帮助。
val time = measureTimeMillis {
val ctx = ExecutionContext()
val df = ctx.csv("/mnt/nyctaxi/csv/yellow_tripdata_2019-01.csv", 1*1024)
.aggregate(
listOf(col("passenger_count")),
listOf(max(cast(col("fare_amount"), ArrowTypes.FloatType))))
val results = ctx.execute(df.logicalPlan())
results.forEach { println(it.toCSV()) }
println("Query took $time ms")
这将在我的台式机上产生如下输出:
1,623259.86
2,492.5
3,350.0
4,500.0
5,760.0
6,262.5
7,78.0
8,87.0
9,92.0
0,36090.3
Query took 36090 ms
结果是一致的,但执行查询所花费的时间大约多了五倍。这充分显现了上一章中所讨论的映射下推优化所带来的好处。
SQL 支持
本章讨论的源代码可以在 KQuery 的 examples 模块中找到。
除了具有手动编码逻辑计划的能力外,在某些情况下,仅编写 SQL 将更加方便。在本章节中,我们将构建一个可以将 SQL 查询转化为逻辑计划的 SQL 解析器和查询规划器。
Tokenizer 分词器
第一步是将 SQL 查询字符串转换为表示关键字、文字、标识符和操作符的令牌列表。
下面是所有可能令牌的子集,目前已经够用了。
interface Token
data class IdentifierToken(val s: String) : Token
data class LiteralStringToken(val s: String) : Token
data class LiteralLongToken(val s: String) : Token
data class KeywordToken(val s: String) : Token
data class OperatorToken(val s: String) : Token
然后我们需要一个 tokenizer 类。在这里介绍这一点不是特别有趣,完整的代码可以在配套的 Github 仓库中找到。
class Tokenizer {
fun tokenize(sql: String): List<Token> {
// see github repo for code
}
}
给定输入 SELECT a + b FROM c,我们期望可以得到以下输出:
listOf(
KeywordToken("SELECT"),
IdentifierToken("a"),
OperatorToken("+"),
IdentifierToken("b"),
KeywordToken("FROM"),
IdentifierToken("c")
)
Pratt Parser
译者注:相关阅读可参考 https://matklad.github.io/2020/04/13/simple-but-powerful-pratt-parsing.html
我们将根据 Vaughan R. Pratt 在 1973 年发表的自顶向下运算符优先级论文,手动编写一个 SQL 解析器。尽管还有其它方法可以构建 SQL 解析器,比如使用解析器生成器和解析器组合器,但我发现 Pratt 的方法很好,而且生成的代码高效,易于理解和调试。
下面是 Pratt 解析器的基本实现。在我看来,它的美丽在于它的简单。表达式解析是通过一个简单的循环来执行的,该循环解析一个 “prefix 前缀” 表达式,然后是可选的 “infix 中缀” 表达式,并继续执行此操作,直到优先级发生改变,使解析器认识到它已经完成了对表达式的解析。当然 parsePrefix 和 parseInfix 实现可以递归地回到 parse 方法中,这就是它变得非常强大的地方。
interface PrattParser {
/** Parse an expression */
fun parse(precedence: Int = 0): SqlExpr? {
var expr = parsePrefix() ?: return null
while (precedence < nextPrecedence()) {
expr = parseInfix(expr, nextPrecedence())
}
return expr
}
/** Get the precedence of the next token */
fun nextPrecedence(): Int
/** Parse the next prefix expression */
fun parsePrefix(): SqlExpr?
/** Parse the next infix expression */
fun parseInfix(left: SqlExpr, precedence: Int): SqlExpr
}
这个接口引用了一个新的 SqlExpr 类,它将作为解析表达式的表示形式,并且在很大程度上将是逻辑计划中定义的表达式的一对一映射。但是对于二元表达式,我们可以使用其中运算符是字符串这种更为通用的结构,而不是为我们将支持的所有不同的二进制表达式创建单独的数据结构。
下面是 SqlExpr 实现的一些示例:
/** SQL Expression */
interface SqlExpr
/** Simple SQL identifier such as a table or column name */
data class SqlIdentifier(val id: String) : SqlExpr {
override fun toString() = id
}
/** Binary expression */
data class SqlBinaryExpr(val l: SqlExpr, val op: String, val r: SqlExpr) : SqlExpr {
override fun toString(): String = "$l $op $r"
}
/** SQL literal string */
data class SqlString(val value: String) : SqlExpr {
override fun toString() = "'$value'"
}
有了这些类,就可以用下面的代码表示表达式 foo = bar。
val sqlExpr = SqlBinaryExpr(SqlIdentifier("foo"), "=", SqlString("bar"))
Parsing SQL Expressions 解析 SQL 表达式
让我们通过这种方式来解析一个简单的数学表达式,例如 1 + 2 * 3。该表达式由以下标记组成。
listOf(
LiteralLongToken("1"),
OperatorToken("+"),
LiteralLongToken("2"),
OperatorToken("*"),
LiteralLongToken("3")
)
我们需要创建 PrattParser 的 trait 特性实现,然后将令牌传递给构造函数。令牌封装在 TokenStream 类中,该类提供了一些方便的方法,例如用于消费下一个令牌的 next,以及当我们希望在不消费令牌的情况下查看时的 peek。
class SqlParser(val tokens: TokenStream) : PrattParser {
}
实现 nextPrecedence 方法很简单,因为这里只有少量具任何优先级的令牌,并且我们需要使乘法和除法运算符具有比加减法运算符更高的优先级。注意,这个方法返回的具体数字并不重要,因为它们只是用于比较。在 PostgreSQL 文档 中可以找到一个很好的运算符优先级参考。
override fun nextPrecedence(): Int {
val token = tokens.peek()
return when (token) {
is OperatorToken -> {
when (token.s) {
"+", "-" -> 50
"*", "/" -> 60
else -> 0
}
}
else -> 0
}
}
前缀解析器只需要知道如何解析字面数值。
override fun parsePrefix(): SqlExpr? {
val token = tokens.next() ?: return null
return when (token) {
is LiteralLongToken -> SqlLong(token.s.toLong())
else -> throw IllegalStateException("Unexpected token $token")
}
}
中缀解析器只需要知道如何解析运算符。注意,在解析运算符之后,此方法将递归地回调倒顶层解析方法,以解析运算符后面的表达式(二元表达式的右侧)。
override fun parseInfix(left: SqlExpr, precedence: Int): SqlExpr {
val token = tokens.peek()
return when (token) {
is OperatorToken -> {
tokens.next()
SqlBinaryExpr(left, token.s, parse(precedence) ?:
throw SQLException("Error parsing infix"))
}
else -> throw IllegalStateException("Unexpected infix token $token")
}
}
优先级逻辑可以通过解析数学表达式 1 + 2 * 3 和 1 * 2 + 3来证明,它们应该分别被解析为 1 + (2 * 3) 和 (1 * 2) + 3。
例如:解析 1 + 2 _ 3 *。
以下是令牌及其优先级值。
Tokens: [1] [+] [2] [*] [3]
Precedence: [0] [50] [0] [60] [0]
最终结果将表达式正确地表述为 1 + (2 * 3)。
SqlBinaryExpr(
SqlLong(1),
"+",
SqlBinaryExpr(SqlLong(2), "*", SqlLong(3))
)
例如:解析 1 _ 2 + 3*。
Tokens: [1] [*] [2] [+] [3]
Precedence: [0] [60] [0] [50] [0]
最终结果将表达式正确地表述为 (1 * 2) + 3。
SqlBinaryExpr(
SqlBinaryExpr(SqlLong(1), "*", SqlLong(2)),
"+",
SqlLong(3)
)
Parsing a SELECT statement 解析 SELECT 语句
现在我们已经能够解析一些简单地表达式了,下一步是扩展解析器,以支持将 SELECT 语句解析为具体的语法树 (CST)。请注意,对于其它的解析方法,例如使用像 ANTLR 这样的解析生成器,会有一个称为抽象语法树 (AST) 的中间阶段,然后需要将其转换为具体语法树,但是使用 Pratt 解析器方法,我们可以直接从令牌转换为具体语法树。
下面是一个示例 CST,它可以表示带有映射和选择的简易单表查询。将在后面的章节中对齐进行扩展以支持更复杂的查询。
data class SqlSelect(
val projection: List<SqlExpr>,
val selection: SqlExpr,
val tableName: String) : SqlRelation
SQL Query Planner SQL 查询规划器
SQL 查询规划器将 SQL 查询树转换为逻辑计划。由于 SQL 语言的灵活性,这将比逻辑计划转换为物理计划要困难得多。例如,考虑下面的简单查询:
SELECT id, first_name, last_name, salary/12 AS monthly_salary
FROM employee
WHERE state = 'CO' AND monthly_salary > 1000
虽然这对于阅读的人来说很直观,但是查询的选择部分 (WHERE 子句) 引用了一个表达式 (state),该表达式不包含在映射的输出中,因此显然需要在映射前应用,当它同时也应用了另一个表达式 (salary/12 AS monthly_salary),该表达式只有在应用映射后才可用。在使用 GROUP BY、HAVING 和 ORDER BY 子句时,我们也会遇到类似的问题。
这个问题有多种解决方案。一种方案是将此查询转换未以下逻辑计划,将表达式分成两个步骤,一个在映射前,另一个在映射后。但是,这样可行仅仅是因为所选的表达式是一个结合性谓词(只有在所有部分都是正确的情况下,表达式是正确的),而对于更复杂的表达式来说,这种方法可能无法使用。如果该表达式变为 state = 'CO' OR monthly_salary > 1000,那么我们将无法执行此操作。
Filter: #monthly_salary > 1000
Projection: #id, #first_name, #last_name, #salary/12 AS monthly_salary
Filter: #state = 'CO'
Scan: table=employee
一种更加简单通用的方法是将所有必须的表达式加到映射中,以便可以在映射后应用选择,然后通过在另一个映射中封装输出来移除所有多余的列。
Projection: #id, #first_name, #last_name, #monthly_salary
Filter: #state = 'CO' AND #monthly_salary > 1000
Projection: #id, #first_name, #last_name, #salary/12 AS monthly_salary, #state
Scan: table=employee
值得注意的是,我们将在后面的章节中构建一个 "Predicate Push Down" 查询优化器规则,它能够优化该计划,并将谓词的 state = 'CO' 部分推到计划的更下方,使其位于映射之前。
Translating SQL Expressions 转换 SQL 表达式
将 SQL 表达式转换未逻辑表达式相当简单,如本示例代码所示:
private fun createLogicalExpr(expr: SqlExpr, input: DataFrame) : LogicalExpr {
return when (expr) {
is SqlIdentifier -> Column(expr.id)
is SqlAlias -> Alias(createLogicalExpr(expr.expr, input), expr.alias.id)
is SqlString -> LiteralString(expr.value)
is SqlLong -> LiteralLong(expr.value)
is SqlDouble -> LiteralDouble(expr.value)
is SqlBinaryExpr -> {
val l = createLogicalExpr(expr.l, input)
val r = createLogicalExpr(expr.r, input)
when(expr.op) {
// comparison operators
"=" -> Eq(l, r)
"!=" -> Neq(l, r)
">" -> Gt(l, r)
">=" -> GtEq(l, r)
"<" -> Lt(l, r)
"<=" -> LtEq(l, r)
// boolean operators
"AND" -> And(l, r)
"OR" -> Or(l, r)
// math operators
"+" -> Add(l, r)
"-" -> Subtract(l, r)
"*" -> Multiply(l, r)
"/" -> Divide(l, r)
"%" -> Modulus(l, r)
else -> throw SQLException("Invalid operator ${expr.op}")
}
}
else -> throw new UnsupportedOperationException()
}
}
Planning SELECT 规划 SELECT
如果我们只想支持所选列引用也全都存在于映射中,我们也可以使用一些非常简单的逻辑来构建查询计划。
fun createDataFrame(select: SqlSelect, tables: Map<String, DataFrame>) : DataFrame {
// get a reference to the data source
var df = tables[select.tableName] ?:
throw SQLException("No table named '${select.tableName}'")
val projectionExpr = select.projection.map { createLogicalExpr(it, df) }
if (select.selection == null) {
// apply projection
return df.select(projectionExpr)
}
// apply projection then wrap in a selection (filter)
return df.select(projectionExpr)
.filter(createLogicalExpr(select.selection, df))
}
然而,由于选择可以映射的输入和输出,因此我们需要创建一个带有中间映射的更复杂的计划。第一步是通过选择过滤器表达式以确定哪些列是被引用到的。为此,我们将使用访问者模式遍历表达式树,并构建一个可变的列名称集合。
下面是我们将用于遍历表达式树的方法:
private fun visit(expr: LogicalExpr, accumulator: MutableSet<String>) {
when (expr) {
is Column -> accumulator.add(expr.name)
is Alias -> visit(expr.expr, accumulator)
is BinaryExpr -> {
visit(expr.l, accumulator)
visit(expr.r, accumulator)
}
}
}
至此,我们现在可以编写以下代码,将 SELECT 语句转换为有效的逻辑计划。下面的示例代码并不完美,并且在特殊情况下下可能包含一些错误,例如数据源中的列和别名表达式之间存在名称冲突,但是为了保持代码简洁,我们将暂时忽略这一点。
fun createDataFrame(select: SqlSelect, tables: Map<String, DataFrame>) : DataFrame {
// get a reference to the data source
var df = tables[select.tableName] ?:
throw SQLException("No table named '${select.tableName}'")
// create the logical expressions for the projection
val projectionExpr = select.projection.map { createLogicalExpr(it, df) }
if (select.selection == null) {
// if there is no selection then we can just return the projection
return df.select(projectionExpr)
}
// create the logical expression to represent the selection
val filterExpr = createLogicalExpr(select.selection, df)
// get a list of columns references in the projection expression
val columnsInProjection = projectionExpr
.map { it.toField(df.logicalPlan()).name}
.toSet()
// get a list of columns referenced in the selection expression
val columnNames = mutableSetOf<String>()
visit(filterExpr, columnNames)
// determine if the selection references any columns not in the projection
val missing = columnNames - columnsInProjection
// if the selection only references outputs from the projection we can
// simply apply the filter expression to the DataFrame representing
// the projection
if (missing.size == 0) {
return df.select(projectionExpr)
.filter(filterExpr)
}
// because the selection references some columns that are not in the
// projection output we need to create an interim projection that has
// the additional columns and then we need to remove them after the
// selection has been applied
return df.select(projectionExpr + missing.map { Column(it) })
.filter(filterExpr)
.select(projectionExpr.map {
Column(it.toField(df.logicalPlan()).name)
})
}
Planning for Aggregate Queries 规划聚合查询
如你所见,SQL 查询规划器相对复杂,解析聚合查询的代码则更有甚之。如果你对此有兴趣了解更多,请参阅源代码。
Parallel Query Execution 执行并行查询
到目前为止,我们一直使用单个线性对单个文件进行查询。但这种方法的可伸缩性不是很好,因为对于较大的文件或多个文件,查询将花费更长的时间来运行。下一步是实现分布式执行查询,以便其可以利用多个 CPU 核心和多台服务器。
分布式执行查询最简单的形式是利用线程在单个节点上使用多个 CPU 核心执行并行查询。
为了便于处理,纽约市出驻车数据集已经进行了分区,因为每年的每个月都有一个 CSV 文件,这意味着 2019 年的数据集有 12 个分区,执行并行查询的最直接的方法是在每个分区使用一个线程并执行相同的查询,然后将结果组合在一起。假设这段代码运行在具有 6 个 CPU 核心的并支持超线程的计算机上。在这种情况下,这十二个查询的执行时间应该与在单个线程上运行其中一个查询的运行时间相同。
下面是一个跨 12 个分区并行运行聚合 SQL 查询的示例。这个例子是使用 Kotlin 的协程实现的,而不是直接使用线程。
该实例的源代码可以在 KQuery 的 Github 仓库中找到。
让我们从一个单线程代码开始,针对一个分区运行一个查询。
fun executeQuery(path: String, month: Int, sql: String): List<RecordBatch> {
val monthStr = String.format("%02d", month);
val filename = "$path/yellow_tripdata_2019-$monthStr.csv"
val ctx = ExecutionContext()
ctx.registerCsv("tripdata", filename)
val df = ctx.sql(sql)
return ctx.execute(df).toList()
}
准备好后,我们现在可以编写以下代码,以便并行在 12 个数据分区中的每一个分区上都运行此查询。
val start = System.currentTimeMillis()
val deferred = (1..12).map {month ->
GlobalScope.async {
val sql = "SELECT passenger_count, " +
"MAX(CAST(fare_amount AS double)) AS max_fare " +
"FROM tripdata " +
"GROUP BY passenger_count"
val start = System.currentTimeMillis()
val result = executeQuery(path, month, sql)
val duration = System.currentTimeMillis() - start
println("Query against month $month took $duration ms")
result
}
}
val results: List<RecordBatch> = runBlocking {
deferred.flatMap { it.await() }
}
val duration = System.currentTimeMillis() - start
println("Collected ${results.size} batches in $duration ms")
下面是在一台 24 核心台式机上运行的示例的输出:
Query against month 8 took 17074 ms
Query against month 9 took 18976 ms
Query against month 7 took 20010 ms
Query against month 2 took 21417 ms
Query against month 11 took 21521 ms
Query against month 12 took 22082 ms
Query against month 6 took 23669 ms
Query against month 1 took 23735 ms
Query against month 10 took 23739 ms
Query against month 3 took 24048 ms
Query against month 5 took 24103 ms
Query against month 4 took 25439 ms
Collected 12 batches in 25505 ms
如你所见,总持续时间与最慢查询时间大致相同。
尽管我们已经成功地对分区执行了聚合查询,但我们的结果仍是有重复值的数据批列表。例如,很有可能在每个分区内都出现 passenger_count = 1 这样的结果。
Combining Results 合并结果
对于映射和选择运算符组成的简单查询,可以组合并行查询的结果(类似于 SQL 中的 UNION ALL 操作),并且不需要进一步的处理。涉及聚合、排序或连接等更复杂的查询将需要在并行查询的结果上运行辅助查询,以组合结果。术语 "map" 和 "reduce" 经常用于解释这两步的过程。"map" 步骤指的是在分区中并行运行一个查询,"reduce" 步骤是指将结果组合到单个结果中。
对于这个特定的示例,现在需要运行一个次要聚合查询,该查询与针对分区执行的聚合查询几乎相同。其中一个区别是,次要查询可能需要应用不同的集合功能。对于聚合函数 min、max 和 sum,与 map 和 reduce 过程中使用的操作相同,以获取各分区的结果。对于 count 表达式,我们不需要每个分区单独的计数值,而是希望看到计数的总和。
val sql = "SELECT passenger_count, " +
"MAX(max_fare) " +
"FROM tripdata " +
"GROUP BY passenger_count"
val ctx = ExecutionContext()
ctx.registerDataSource("tripdata", InMemoryDataSource(results.first().schema, results))
val df = ctx.sql(sql)
ctx.execute(df).forEach { println(it) }
这最终将产生如下结果:
1,671123.14
2,1196.35
3,350.0
4,500.0
5,760.0
6,262.5
7,80.52
8,89.0
9,97.5
0,90000.0
Smarter Partitioning 更加智能的分区
尽管每个文件使用一个线程的策略在本例中运行良好,但它不能作为通用的分区方法。如果数据源有数千个小分区,那么在每个分区上都启动一个线程的效率会很低。更好的方法是由查询规划器来决定如何在指定数量的工作线程(或执行器)之间共享可用数据。
有些文件格式已经具有自然分区方案。例如,Apache Parquet 文件由多个包含批量列数据的 “行组” 组成。查询规划器可以检查可用的 Parquet 文件,构建行组列表,然后安排在固定数量的线程或执行器中读取这些行组。
甚至可以将此计数应用于非结构化文件,例如 CSV 文件,但这并不是一件容易的事。虽然检查文件大小并将文件分成大小相等的块很容易,但是一条记录可能跨越两个块,因此有必要从边界向后或向前读取以找到记录的起点或重点。查找换行符是不够的,因为这些字符通常也出现在记录中,并也用于界定激励。普遍的做法是将 CSV 文件转换为结构化格式,例如在处理管道前期转换为 Parquet 格式,以提高后续处理的效率。
Partition Keys 分区键
解决此问题的一种方案是将文件放入目录中,并使用键值对组成目录名称来指定内容。
例如我们可以按如下方式组织文件:
/mnt/nyxtaxi/csv/year=2019/month=1/tripdata.csv
/mnt/nyxtaxi/csv/year=2019/month=2/tripdata.csv
...
/mnt/nyxtaxi/csv/year=2019/month=12/tripdata.csv
有了这种结构,查询规划器现在可以实现一种形式的 “谓词下推”,以限制物理查询计划中包含的分区数量。这种方法通常被称为 “partition pruning 分区修剪”。
Parallel Joins 并行连接
当使用单个线程执行内部连接时,一种简单的方法是将连接的一侧加载到内存中,然后扫描另一侧,对存储在内存中的数据执行查找。如果连接的一侧可以放入内存,那么这种经典的哈希连接算法是行之有效的。
这种连接的并行版本称为分区哈希连接或并行哈希连接。它包括基于连接键对两个输入进行分区,并在每个分区上执行传统的哈希连接。
Distributed Query Execution 执行分布式查询
上一节关于并行查询执行的内容涵盖了一些基本概念,例如分区,本节将在此基础上进行构建。
为了稍微简化执行分布式查询的概念,我们的目标是创建一个物理查询计划,该计划定义如何将工作分配给集群中的许多 “执行者”。分布式查询计划通常包含新的运算符,这些运算符描述了在请求执行期间数据是如何在不同时间点上与不同的执行者之间进行交换的。
在下面的部分中,我们将深入探讨如何在分布式环境中执行不同类型的计划,然后讨论如何构建分布式查询调度器。
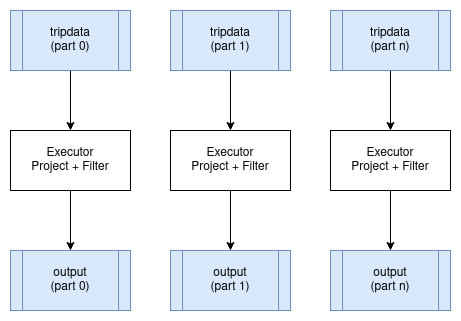
Embarrassingly Parallel Operators 令人尴尬的并行运算符
在分布式环境下运行时,某些运算符可以在数据分区上并行运行,而不会产生任何显著的开销。最好的例子就是映射和过滤。这些运算符可以并行地应用于正在操作数据的每个输入分区,并为每个输入分区生成相应的输出分区。这些运算符不会改变数据分区方案。
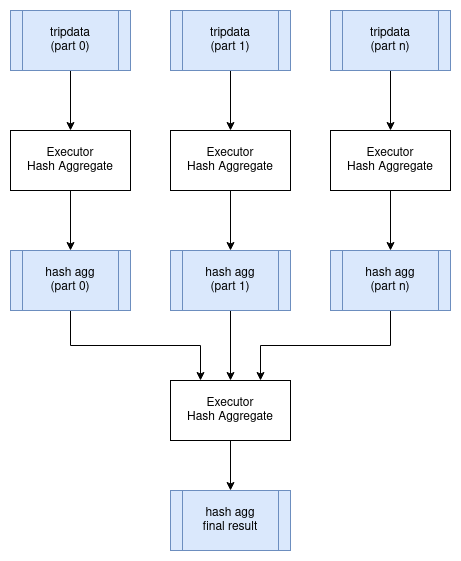
Distributed Aggregates 分布式聚合
让我们使用在上一章节执行并行查询中所用的 SQL 查询示例,并观察聚合查询在分布式计划中的含义。
SELECT passenger_count, MAX(max_fare)
FROM tripdata
GROUP BY passenger_count
我们可以在 tripdata 表的所有分区上并行执行此查询,集群中的每个执行处理器负责这些分区的一部分。但是,我们需要将所有的结果聚合数据合并到单个节点上,才能应用最终的聚合查询,以便获得一个没有重复的分组键(本例中为 passenger_count) 的结果集合。下面是一个可能代表这种情况的逻辑查询计划。注意,新的 Exchange 操作符表示执行器之间的数据交换。交换的物理计划可以通过将中间结果写入共享存储来实现,或者可以通过将数据直接以流的形式传输到其它执行器来实现。
HashAggregate: groupBy=[passenger_count], aggr=[MAX(max_fare)]
Exchange:
HashAggregate: groupBy=[passenger_count], aggr=[MAX(max_fare)]
Scan: tripdata.parquet
下图展示了如何在分布式环境中执行此查询:
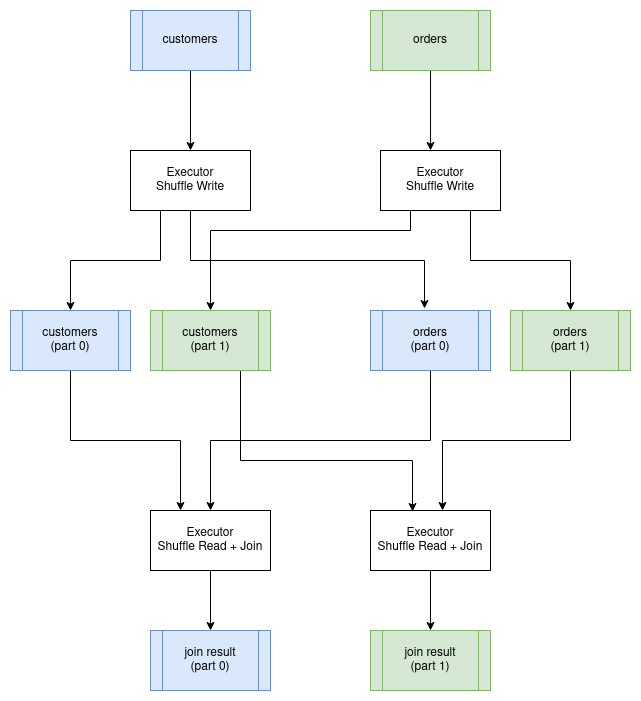
Distributed Joins 分布式连接
连接通常是在分布式环境中执行的最昂贵的操作。这样说的原因是,我们需要确保在组织数据时,两个输入关系都根据连接键进行了分区。例如,如果我们把 customer 表连接到 order 表,其中连接的条件是 customer.id = order.customer_id,则两个表中针对特定客户的所有行必须由同一执行器处理。要实现这一点,我们必须受限对连接键上的两个表进行重新分区,并将分区写入磁盘。一旦完成,我们就可以对每个分区并行地执行连接了。结果数据仍将按连接键进行分区。这种特殊的连接算法称为分区哈希连接。重新划分数据地过程称为执行 "shuffle"。
Distirbuted Query Scheduling 分布式查询调度
分布式查询计划与进程内查询计划有本质上地不同,因为我们不能仅仅构建一个运算符树并开始执行它们。现在的查询需要跨执行器进行协调,这意味着我们现在开始需要构建一个调度器。
在高层次上,分布式查询调度器的概念并不复杂。调度器需要检查整个查询,并将其分解为可以单独主席那个的阶段(通常跨执行器并行执行),然后根据集群中的可用资源调度执行这些阶段。一旦每个查询阶段完成,就可以安排任何后续的依赖性查询阶段。直到所有查询都被执行完成前都重复这一过程。
调度器还可以负责管理集群中的计算资源,以便可以根据需要启动额外的执行器来处理查询负载。
在本章节的其余部分,我们将讨论以下主题,即 Ballista 和该项目中实现的设计。
- 生成分布式查询计划
- 序列化查询计划并于执行器交换
- 在执行器之间交换中间结果
- 优化分布式查询
Producing a Distributed Query Plan 生成分布式查询计划
正如我们在前例中看到的那样,一些运算符可以在输入分区上并行运行,而另一些运算符需要对数据进行重新分区。分区中的这些变动是规划分布式查询的关键。计划中的分区变更有时称为管道中断,分区时的这些变更定义了查询阶段之间的边界。
现在我们将使用下面的 SQL 查询来了解这个过程具体是如何工作的:
SELECT customer.id, sum(order.amount) as total_amount
FROM customer JOIN order ON customer.id = order.customer_id
GROUP BY customer.id
该查询的(非分布式)物理计划如下所示:
Projection: #customer.id, #total_amount
HashAggregate: groupBy=[customer.id], aggr=[MAX(max_fare) AS total_amount]
Join: condition=[customer.id = order.customer_id]
Scan: customer
Scan: order
假设 customer 和 order 表还没有根据 customer id 进行分区,我们将需要调度执行前两个查询阶段,以对该数据进行重新分区。这两个查询阶段可以并行。
Query Stage #1: repartition=[customer.id]
Scan: customer
Query Stage #2: repartition=[order.customer_id]
Scan: order
接下来,我们可以调度连接,它将在两个输入的各个分区并行运行。连接之后的下一个运算符是聚合,它被分成两部分:并行前的聚合,然后是需要变成单个输入分区的最终聚合。我们可以在与连接相同的查询阶段执行此聚合的并行部分,因为第一个聚合不关心数据如何分区。然后来到第三个查询阶段,让我们现在开始调度执行。此查询阶段的输出仍然按客户 id 进行分区。
Query Stage #3: repartition=[]
HashAggregate: groupBy=[customer.id], aggr=[MAX(max_fare) AS total_amount]
Join: condition=[customer.id = order.customer_id]
Query Stage #1
Query Stage #2
最后一个查询阶段执行聚合,从前一个阶段的所有分区中读取数据。
Query Stage #4:
Projection: #customer.id, #total_amount
HashAggregate: groupBy=[customer.id], aggr=[MAX(max_fare) AS total_amount]
QueryStage #3
稍作回顾,下面是完整的分布式查询计划,其中显示了当需要在管道操作之间重新分区或交换数据时引入的查询阶段。
Query Stage #4:
Projection: #customer.id, #total_amount
HashAggregate: groupBy=[customer.id], aggr=[MAX(max_fare) AS total_amount]
Query Stage #3: repartition=[]
HashAggregate: groupBy=[customer.id], aggr=[MAX(max_fare) AS total_amount]
Join: condition=[customer.id = order.customer_id]
Query Stage #1: repartition=[customer.id]
Scan: customer
Query Stage #2: repartition=[order.customer_id]
Scan: order
Serializing a Query Plan 序列化查询计划
查询调度器需要将整个查询计划的片段发送给执行程序执行。
有许多选项可以用于序列化查询计划,以便在进程之间传递查询计划。许多查询引擎选择使用编程语言原生支持序列化的策略。如果不需要跨编程语言交换查询计划,那这无疑是一个合适的选择,而且这通常是最简单的实现机制。
然而,使用于编程语言无关的序列化格式是有好处的。Ballista 使用 Google 的 Protocol Buffers 格式来定义查询计划。该项目通常缩写为 "protobuf"。
下面是在 Ballista 的 protobuf 中定义的部分查询计划。
完整的源代码可以在 Ballista 的 github 仓库中找到。
译者注:由于 Ballista 现已移归到 Apache-Arrow 项目中,因此新的地址改为 https://github.com/apache/arrow-datafusion/blob/main/datafusion/proto/proto/datafusion.proto
message LogicalPlanNode {
LogicalPlanNode input = 1;
FileNode file = 10;
ProjectionNode projection = 20;
SelectionNode selection = 21;
LimitNode limit = 22;
AggregateNode aggregate = 23;
}
message FileNode {
string filename = 1;
Schema schema = 2;
repeated string projection = 3;
}
message ProjectionNode {
repeated LogicalExprNode expr = 1;
}
message SelectionNode {
LogicalExprNode expr = 2;
}
message AggregateNode {
repeated LogicalExprNode group_expr = 1;
repeated LogicalExprNode aggr_expr = 2;
}
message LimitNode {
uint32 limit = 1;
}
Protobuf 项目提供了用于生成特定语言源代码的工具 (protoc),以序列化和反序列化数据。
Serializing Data 序列化数据
数据在客户端和执行器之间以及执行器与执行器之间进行流传输的时候也必须进行序列化。
Apache Arrow 提供了一种 IPC(程间通讯)格式,用于在进程之间交换数据。由于 Arrow 提供了标准化的内存布局,因此可以直接在内存和输入/输出设备(磁盘、网络等)之间传输原始字节,而没有常规的与序列化相关的开销。这实际上是一个 zero copy 操作,因为数据不必从其所在内存中的格式,转换为单独的序列化格式。
但是,关于数据的元数据,例如 schema 模式(列名和数据类型)确实需要使用 Google Flatbuffers 进行编码。 此元数据很小,并且通常每个结果集或每个批处理序列化一次,因此开销很小。
使用 Apache Arrow 的另一个优点是,它在不同编程语言之间提供了非常有效的数据交换。
IPC 定义了数据编码格式,但是没有定义交换机制。例如,Arrow IPC 可以通过 JNI 将数据从 JVM 语言传输到 C 或者 Rust。
Choosing a Protocol 选择协议
既然我们已经为查询计划和数据选择了序列化格式,下一个问题是如何在分布式进程之间交换这些数据。
Apache Arrow 为此提供了一个 Flight 协议。Flight 是一种新的通用 C/S 框架,用于简化大型数据集在网络接口上高性能传输实现。
Arrow Flight 库提供了一个开发框架,用于实现可以发送和接收数据流的服务。Flight 服务端支持了几种基本类型的请求:
- Handshake: 一个简单的请求,以确定客户端是否被授权,在某些情况下,也可以建立一个实现定义的会话令牌,以供未来的请求使用
- ListFlights: 返回可用的数据流列表
- GetSchema: 返回数据流的模式
- GetFlightInfo: 返回关注的数据集的 “访问计划”,可能需要使用多个数据流。此请求可以接收包含特定应用程序参数的自定义序列化命令
- DoGet: 将数据流发送到客户端
- DoPut: 从客户端接收数据流
- DoAction: 执行特定于实现的操作并返回任意结果,即通用函数调用
- ListActions: 返回可用操作类型的列表
例如,GetFlightInfo 方法可用于编译查询计划并返回接收结果所需的信息,然后再每个执行器上调用 DoGet 以开始接收来自查询的结果。
Streaming 流
可以尽快提供查询结果,并将其流式传输到需要对该数据进行运算的下一个进程,这一点很重要,否则将出现不可接受的延迟,因为每个运算都必须等待前一个运算完成。
但是,有些运算符需要在产生任何输出之前接收所有输入数据。排序操作就是一个很好的例子。在接收到整个数据集之前,不可能对数据集进行完全排序。这个问题可以通过增加分区的数量来缓解,这样大量的分区可以并行排序,然后可以使用合并操作有效地组合排序后的批次数据。
Custom Code 自定义代码
通常需要将自定义代码作为分布式查询或计算的一部分来运行。对于单语言查询引擎,通常可以使用该语言的内置序列化机制在查询期间通过网络传输此代码,这在开发过程中非常方便。另一种方法式将编译后的代码发布到存储库,以便在运行时将其下载到集群中。对于基于 JVM 的系统,可以使用 maven 存储库。更通用的方法是将所有运行时的依赖打包到 Docker 镜像中。
查询计划需要提供必要的信息,以便在运行时加载用户代码。对于基于 JVM 的系统,这可以是一个类路径和一个类名。对于基于 C 的系统,这可能是一个共享对象的路径。无论哪种情况,用户代码都需要实现一些已知的 API。
分布式查询优化
与在单个主机上执行并行查询相比,分布式查询有很多额外开销,所以只有这样做有好处的时候才应该使用。关于这个画图ide一些有趣光电,我推荐阅读论文 Scalability! But at what COST?。
另外,有许多方法可以分发相同的查询,所以我们如何知道该使用哪一种呢?
其中一种解决方法是构建一种机制来确定执行特定查询计划的开销,然后为给定问题创建所有可能的查询计划组合的某个子集,并确定哪一个最为高效。
计算运算开销涉及到许多因素,并且涉及不同的资源和成本限制。
- Memory: 我们通常关心的是内粗你的可用性,而不是性能。在内存中处理数据要比在硬盘上读写快几个数量级。
- CPU: 对于可并行的工作负载,更多的 CPU 核心意味着更好的吞吐量
- GPU: 有些运算在 GPU 上要比 CPU 快几个数量级
- Disk: 硬盘的读写速度有限,云供应商通常会限制每秒 I/O 操作的数量 (IOPS)。不同类型的硬盘具有不同的性能特性(机械硬盘 vs SSD vs NVMe)
- Network: 分布式查询的执行涉及节点之间的数据流。网络基础设施限制了吞吐量
- Distributed Storage: 源数据存储在分布式文件系统 (HDFS) 或对象存储 (Amazon S3, Azure Blob Storage) 中,并且在分布式存储和本地文件系统之间传输数据是有开销的
- Data Size: 数据量大小也很重要。当在两个表之间执行连接并且需要通过网络传输数据时,最好传输两个表中较小的表。如果其中一个表可以装入内存,则可以使用更有效的连接操作
- Monetary Cost: 如果一个查询可以以三倍的成本加速 10%,那么这样做是否值得?当然,这个问题最好由用户来回答。通常通过限制可用的计算资源量来控制货币成本
如果提前知道足够多的数据相关信息,例如数据又多大、查询中使用的连接件的分区基数、分区数量等。那么可以使用算法预先计算查询成本。这一切都取决于查询的数据集的某些可用统计信息。
另一种方法是开始运行查询,并让每个运算符根据接收到的输入数据进行调整。Apache Spark 3.0.0 引入了一个自适应查询执行功能,它可以做到这一点。
Testing 测试
查询引擎非常复杂,很容易在无意中引入细微的错误,从而导致查询返回不正确的结果,因此进行严格的测试非常重要。
Unit Testing 单元测试
最好是在第一步是为单个运算符和表达式编写单元测试,用断言来限定给定的输入产生正确的输出。当然错误情况的处理也很重要。
以下是一些在编写单元测试时需要考虑的建议:
- 如果使用了意外的数据类型会发生什么?例如,对于字符串输入进行
SUM求和 - 测试应该涵盖极端情况,例如对数字数据类型使用最小值和最大值,对浮点类型使用 Nan (不是数字),以确保它们能够被正确处理
- 也应该针对上下溢出的情况进行测试。例如,当两个
long(64位) 整数类型相乘时会发生什么? - 测试还应该确保 null 能够被正确处理
在编写这些测试时,重要的是能够使用任意数据构造记录批和列向量,以用作运算符和表达式的输入。下面是这种实用方法的一个示例:
private fun createRecordBatch(schema: Schema,
columns: List<List<Any?>>): RecordBatch {
val rowCount = columns[0].size
val root = VectorSchemaRoot.create(schema.toArrow(),
RootAllocator(Long.MAX_VALUE))
root.allocateNew()
(0 until rowCount).forEach { row ->
(0 until columns.size).forEach { col ->
val v = root.getVector(col)
val value = columns[col][row]
when (v) {
is Float4Vector -> v.set(row, value as Float)
is Float8Vector -> v.set(row, value as Double)
...
}
}
}
root.rowCount = rowCount
return RecordBatch(schema, root.fieldVectors.map { ArrowFieldVector(it) })
}
下面是针对包含双精度浮点值的两列记录批,计算 “大于等于” (>=) 表达式的单元测试示例。
@Test
fun `gteq doubles`() {
val schema = Schema(listOf(
Field("a", ArrowTypes.DoubleType),
Field("b", ArrowTypes.DoubleType)
))
val a: List<Double> = listOf(0.0, 1.0,
Double.MIN_VALUE, Double.MAX_VALUE, Double.NaN)
val b = a.reversed()
val batch = createRecordBatch(schema, listOf(a,b))
val expr = GtEqExpression(ColumnExpression(0), ColumnExpression(1))
val result = expr.evaluate(batch)
assertEquals(a.size, result.size())
(0 until result.size()).forEach {
assertEquals(if (a[it] >= b[it]) 1 else 0, result.getValue(it))
}
}
Integration Testing 集成测试
单元测试就绪后,下一步是编写集成测试,执行多个运算符和表达式组成的查询,并断言它们按预期产生输出。
有几种流行的方法可以对查询引擎进行集成测试:
- Imperative Testing 命令式测试: 硬编码查询和预期结果,要么写成代码,要么存储位包含查询和结果的文件。
- Comparative Testing 比较测试: 此方法涉及对另一个(值得信赖的)查询引擎进行查询,并断言两个查询引擎都产生了相同的结果。
- Fuzzing 模糊: 生成随机运算符和表达式树来捕获边缘特殊情况,并获得全面测试覆盖率。
Fuzzing 模糊
由于运算符和表达式树嵌套的特性,运算符和表达式可以无限组合在一起,查询引擎之所以如此复杂很大程度上都来源于这个事实,手工编码测试查询不可能面面俱到。
模糊测试是一种产生随机输入数据的计数。当应用于查询引擎时,这意味着创建随机查询计划。
下面是一个针对 DataFrame 创建随机表达式的示例。这事一种递归方法,可以产生具有深层嵌套结构的表达式树,因此以最大深度构建机制非常重要。
fun createExpression(input: DataFrame, depth: Int, maxDepth: Int): LogicalExpr {
return if (depth == maxDepth) {
// return a leaf node
when (rand.nextInt(4)) {
0 -> ColumnIndex(rand.nextInt(input.schema().fields.size))
1 -> LiteralDouble(rand.nextDouble())
2 -> LiteralLong(rand.nextLong())
3 -> LiteralString(randomString(rand.nextInt(64)))
else -> throw IllegalStateException()
}
} else {
// binary expressions
val l = createExpression(input, depth+1, maxDepth)
val r = createExpression(input, depth+1, maxDepth)
return when (rand.nextInt(8)) {
0 -> Eq(l, r)
1 -> Neq(l, r)
2 -> Lt(l, r)
3 -> LtEq(l, r)
4 -> Gt(l, r)
5 -> GtEq(l, r)
6 -> And(l, r)
7 -> Or(l, r)
else -> throw IllegalStateException()
}
}
}
下面是使用此方法生成表达式的示例。请注意,列应用在这里用哈希之后的索引表示,例如 #1 表示索引为 1 的列。几乎可以肯定,此表达式无效(取决于查询引擎的实现),并且在使用 fuzzer 时可以预期到。但这仍然很有价值,因为它将测试错误条件,否则在手动编写测试的时候不一定能够涵盖这些。
#5 > 0.5459397414890019 < 0.3511239641785846 OR 0.9137719758607572 > -6938650321297559787 < #0 AND #3 < #4 AND 'qn0NN' OR '1gS46UuarGz2CdeYDJDEW3Go6ScMmRhA3NgPJWMpgZCcML1Ped8haRxOkM9F' >= -8765295514236902140 < 4303905842995563233 OR 'IAseGJesQMOI5OG4KrkitichlFduZGtjXoNkVQI0Alaf2ELUTTIci' = 0.857970478666058 >= 0.8618195163699196 <= '9jaFR2kDX88qrKCh2BSArLq517cR8u2' OR 0.28624225053564 <= 0.6363627130199404 > 0.19648131921514966 >= -567468767705106376 <= #0 AND 0.6582592932801918 = 'OtJ0ryPUeSJCcMnaLngBDBfIpJ9SbPb6hC5nWqeAP1rWbozfkPjcKdaelzc' >= #0 >= -2876541212976899342 = #4 >= -3694865812331663204 = 'gWkQLswcU' != #3 > 'XiXzKNrwrWnQmr3JYojCVuncW9YaeFc' >= 0.5123788261193981 >= #2
在创建逻辑计划的时候也可以采用类似的方法。
fun createPlan(input: DataFrame,
depth: Int,
maxDepth: Int,
maxExprDepth: Int): DataFrame {
return if (depth == maxDepth) {
input
} else {
// recursively create an input plan
val child = createPlan(input, depth+1, maxDepth, maxExprDepth)
// apply a transformation to the plan
when (rand.nextInt(2)) {
0 -> {
val exprCount = 1.rangeTo(rand.nextInt(1, 5))
child.project(exprCount.map {
createExpression(child, 0, maxExprDepth)
})
}
1 -> child.filter(createExpression(input, 0, maxExprDepth))
else -> throw IllegalStateException()
}
}
}
下面是该diamagnetic生成的逻辑查询计划的示例:
Filter: 'VejBmVBpYp7gHxHIUB6UcGx' OR 0.7762591612853446
Filter: 'vHGbOKKqR' <= 0.41876514212913307
Filter: 0.9835090312561898 <= 3342229749483308391
Filter: -5182478750208008322 < -8012833501302297790
Filter: 0.3985688976088563 AND #1
Filter: #5 OR 'WkaZ54spnoI4MBtFpQaQgk'
Scan: employee.csv; projection=None
这种直接的模糊测试方法大概率将产生无效计划。可以通过添加更多上下文感知来对其加以改进,以减少创建无效逻辑计划和表达式的风险。例如,生成 AND 表达式可以生成左右表达式并产生布尔结果。然而,只创建正确的计划是有风险的,因为它可能会限制测试覆盖率。理想情况下,应该可以为 fuzzer 配置生成具有不同特征查询计划的规则。
Benchmarks 基准测试
每个查询引擎在性能、可扩展性和资源需求方面都是独特的,通常有不同的权衡。重要的是拥有良好的基准来了解性能和可扩展性特征。
Measuring Performance 性能评估
性能通常是最简单的评估特征,通常是指执行特定操作所需的时间。例如,可以构建基准来评估特定查询或查询类别的性能。
基准测试通常涉及多次执行查询并测量运行时间。
Measuring Scalability 可扩展性评估
可扩展性是一个很宽泛的术语,有许多不同方面的可扩展性。术语上的可扩展性通常指性能如何随着影响性能的某些变量的值不同而变化。
一个例子是当请求 10GB、100GB 或者 1TB 数据时对性能的影响,随着总数据大小的增加而评估可扩展性。一个常见的目标是使之呈现线性可扩展性,这意味着查询 100GB 数据的时间应该是查询 10GB 数据时间的 10 倍。线性可扩展性让使用者更容易推断预期的行为。
其它影响性能的变量示例如下:
- 并发用户、请求或查询的数量
- 数据分区数
- 物理硬盘数量
- 核心数量
- 节点数量
- 可用内存
- 硬件类型(例如,树莓派和台式机)
Concurrency 并发性
在基于并发请求数量评估可扩展性时,我们通常对吞吐量更感兴趣(每段时间内执行的查询总数),而不是单个查询的持续时间,尽管我们通常也会收集这些信息。
Automation 自动化
运行基准测试通常非常耗时,因此自动化是必不可少的,这样可以进程运行基准测试,可能是每天一次,也可能是每周一次,这样就可以及早发现任何性能退化。
自动化对于保证基准测试的执行一致性以及收集和分析结果时可能需要的所有相关细节也很重要。
下面是执行基准测试时应该收集的数据类型示例:
Hardware Configuration 硬件配置
- 硬件类型
- CPU 核心数量
- 可用内存和硬盘空间
- 操作系统名称和版本
Environment 环境
- 环境变量(小心,不要泄露机要)
Benchmark Configuration 基准测试配置
- 使用的基准测试软件版本
- 被测软件的版本
- 任何配置参数或文件
- 查询的所有数据文件的文件名
- 数据文件大小和校验和
- 已执行查询的详细信息
基准测试结果
- 基准测试开始的日期/时间
- 每次请求的起止时间
- 任何失败查询的错误信息
Comparing Benchmarks 比较基准测试
比较不同版本之间的基准测试是很重要的,这样性能特征的变化就很明显,可以进一步研究。基准测试产生的大量数据通常很难手动比较,因此构建工具来协助完成此事或有裨益。
工具不是直接比较两组性能数据,而是数据的 “差异”,并显示同一基准的两次或多次运行之间的性能百分比差异。能够生成显示多个基准测试运行的图标也很有用。
Publishing Benchmark Results 发布基准测试结果
下面是一些真实基准测试结果的示例,将 Ballista 中 Rust 和 JVM 执行器方案与 Apache Spark 的查询执行时间进行比较。尽管从这些数据中可以清楚地看到 Rust 执行器表现良好,但通过生成图标可以更好的表达这一点。
| CPU 核心数 | Ballista Rust | Ballista JVM | Apache Spark |
|---|---|---|---|
| 3 | 21.431 | 51.143 | 56.557 |
| 6 | 9.855 | 26.002 | 30.184 |
| 9 | 6.51 | 24.435 | 26.401 |
| 12 | 5.435 | 17.529 | 18.281 |
与其绘制查询执行时间的图标,不如绘制吞吐量的图表。吞吐量(以每分钟查询数为单位)可以通过将 60 秒除以执行时间来计算。如果在单个线程上执行一个查询要 5 秒,那么每分钟应该可以运行 12 个查询。
下面是一个示例图表,显示了随着 CPU 内核数量的增加,吞吐量的可扩展性。

Transaction Processing Council (TPC) Benchmarks 事务处理性能委员会基准
事务处理委员会是一个数据库供应商的联盟,他们协作创建和维护各种数据库基准套件,以便在供应商的系统之间进行公平的比较。目前 TPC 的成员公司包括微软、甲骨文、IBM、惠普企业、AMD、英特尔和英伟达。
第一个基准是 TPC-A,于 1989 年发布,此后又创建了其它基准。TPC-C 是一个知名的 OLTP (OnLine Transaction Processsing 联机事务处理) 基准,常用于比较传统 RDBMS 数据库。而 TPC-H (已停止维护) 和 TPC-DS 通常用于测量 "大数据" 查询引擎的性能。
TPC 基准被视为业界的 “黄金标准”,但完全实施起来既复杂又费时。此外,这些基准的结果只能由 TPC 成员发布,并且只有在 TPC 对基准进行审计后才能发布。以 TPC-DS 为例,在撰写本文时,发布官方成绩的公司只有阿里巴巴、H2C、超微和 Databricks。
虽然如此,但 TPC 有一项合理使用政策,允许非成员基于 TPC 基准创建非官方的基准,只要遵守某些条件,比如在使用术语 TPC 之前加上 “源自 TPC”——“源自于 TPC-DS Query 14 的查询性能基准”。也必须维护 TPC 的版权声明和许可协议。可以发布的指标类型也有限制。
许多开源项目只是测量从 TPC 基准套件中执行单个查询的时间,并将其作为跟踪性能的一种方式,并与其它查询引擎进行比较。
更多资源
我希望本书对你有所帮助,并且你现在对查询引擎内部结构应该有了更好的理解。如果你觉得有一些主题没有被充分纳入,或者根本没有,我很乐意听你告知,这样我就可以考虑在这本书未来的修订版中添加其它内容。
反馈可以发布在 LeanPub 网站 的公共论坛上,也可以通过 @andygrove_io 直接向我发送消息。
Open-Source Projects 开源项目
有许多包含查询引擎的开源项目,并且使用这些项目有益于了解相关主题。下面是一些流行的开源查询引擎举例:
- Apache Arrow
- Apache Calcite
- Apache Drill
- Apache Hadoop
- Apache Hive
- Apache Impala
- Apache Spark
- Facebook Presto
- NVIDIA RAPIDS Accelerator for Apache Spark
YouTube
我最近才发现 Andy Pavlo 的系列讲座可以在 YouTube 上找到 (这里)。其中涵盖的不仅仅是查询引擎,还有关于查询优化和执行的更广泛的内容。我强烈推荐大家观看这些视频。
Sample Data 样本数据
较早的章节参考了纽约市出租车和豪华轿车委员会旅行记录数据集。黄色和绿色的出租车旅行记录包括捕获的上下车日期/时间、接送地点、旅行距离、列出票价、费率类型、付费类型以及驾驶员报告的乘客数量等字段。数据以 CSV 格式提供。KQuery 项目包含用于将这些 CSV 文件转换为 Parquet 格式的源代码。
数据可以通过网站连接或者直接访问 S3 下载文件。例如,Linux 或者 Mac 用户可以使用 curl 或 wget 通过以下命令下载黄色出租车 2019 年 1 月的数据,并根据文件名约定创建脚本下载其它文件。
wget https://s3.amazonaws.com/nyc-tlc/trip+data/yellow_tripdata_2019-01.csv