Distributed Query Execution 执行分布式查询
上一节关于并行查询执行的内容涵盖了一些基本概念,例如分区,本节将在此基础上进行构建。
为了稍微简化执行分布式查询的概念,我们的目标是创建一个物理查询计划,该计划定义如何将工作分配给集群中的许多 “执行者”。分布式查询计划通常包含新的运算符,这些运算符描述了在请求执行期间数据是如何在不同时间点上与不同的执行者之间进行交换的。
在下面的部分中,我们将深入探讨如何在分布式环境中执行不同类型的计划,然后讨论如何构建分布式查询调度器。
Embarrassingly Parallel Operators 令人尴尬的并行运算符
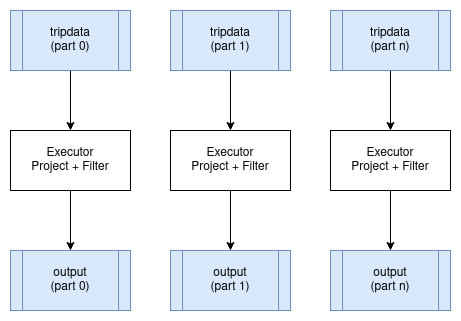
在分布式环境下运行时,某些运算符可以在数据分区上并行运行,而不会产生任何显著的开销。最好的例子就是映射和过滤。这些运算符可以并行地应用于正在操作数据的每个输入分区,并为每个输入分区生成相应的输出分区。这些运算符不会改变数据分区方案。
Distributed Aggregates 分布式聚合
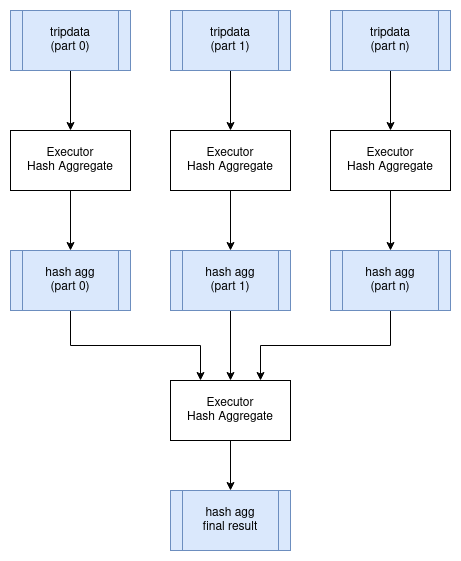
让我们使用在上一章节执行并行查询中所用的 SQL 查询示例,并观察聚合查询在分布式计划中的含义。
SELECT passenger_count, MAX(max_fare)
FROM tripdata
GROUP BY passenger_count
我们可以在 tripdata 表的所有分区上并行执行此查询,集群中的每个执行处理器负责这些分区的一部分。但是,我们需要将所有的结果聚合数据合并到单个节点上,才能应用最终的聚合查询,以便获得一个没有重复的分组键(本例中为 passenger_count) 的结果集合。下面是一个可能代表这种情况的逻辑查询计划。注意,新的 Exchange 操作符表示执行器之间的数据交换。交换的物理计划可以通过将中间结果写入共享存储来实现,或者可以通过将数据直接以流的形式传输到其它执行器来实现。
HashAggregate: groupBy=[passenger_count], aggr=[MAX(max_fare)]
Exchange:
HashAggregate: groupBy=[passenger_count], aggr=[MAX(max_fare)]
Scan: tripdata.parquet
下图展示了如何在分布式环境中执行此查询:
Distributed Joins 分布式连接
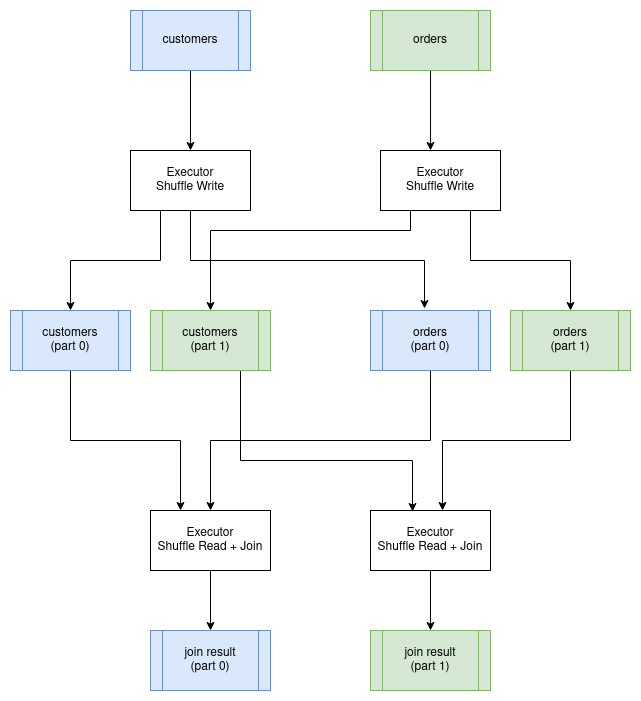
连接通常是在分布式环境中执行的最昂贵的操作。这样说的原因是,我们需要确保在组织数据时,两个输入关系都根据连接键进行了分区。例如,如果我们把 customer 表连接到 order 表,其中连接的条件是 customer.id = order.customer_id,则两个表中针对特定客户的所有行必须由同一执行器处理。要实现这一点,我们必须受限对连接键上的两个表进行重新分区,并将分区写入磁盘。一旦完成,我们就可以对每个分区并行地执行连接了。结果数据仍将按连接键进行分区。这种特殊的连接算法称为分区哈希连接。重新划分数据地过程称为执行 "shuffle"。
Distirbuted Query Scheduling 分布式查询调度
分布式查询计划与进程内查询计划有本质上地不同,因为我们不能仅仅构建一个运算符树并开始执行它们。现在的查询需要跨执行器进行协调,这意味着我们现在开始需要构建一个调度器。
在高层次上,分布式查询调度器的概念并不复杂。调度器需要检查整个查询,并将其分解为可以单独主席那个的阶段(通常跨执行器并行执行),然后根据集群中的可用资源调度执行这些阶段。一旦每个查询阶段完成,就可以安排任何后续的依赖性查询阶段。直到所有查询都被执行完成前都重复这一过程。
调度器还可以负责管理集群中的计算资源,以便可以根据需要启动额外的执行器来处理查询负载。
在本章节的其余部分,我们将讨论以下主题,即 Ballista 和该项目中实现的设计。
- 生成分布式查询计划
- 序列化查询计划并于执行器交换
- 在执行器之间交换中间结果
- 优化分布式查询
Producing a Distributed Query Plan 生成分布式查询计划
正如我们在前例中看到的那样,一些运算符可以在输入分区上并行运行,而另一些运算符需要对数据进行重新分区。分区中的这些变动是规划分布式查询的关键。计划中的分区变更有时称为管道中断,分区时的这些变更定义了查询阶段之间的边界。
现在我们将使用下面的 SQL 查询来了解这个过程具体是如何工作的:
SELECT customer.id, sum(order.amount) as total_amount
FROM customer JOIN order ON customer.id = order.customer_id
GROUP BY customer.id
该查询的(非分布式)物理计划如下所示:
Projection: #customer.id, #total_amount
HashAggregate: groupBy=[customer.id], aggr=[MAX(max_fare) AS total_amount]
Join: condition=[customer.id = order.customer_id]
Scan: customer
Scan: order
假设 customer 和 order 表还没有根据 customer id 进行分区,我们将需要调度执行前两个查询阶段,以对该数据进行重新分区。这两个查询阶段可以并行。
Query Stage #1: repartition=[customer.id]
Scan: customer
Query Stage #2: repartition=[order.customer_id]
Scan: order
接下来,我们可以调度连接,它将在两个输入的各个分区并行运行。连接之后的下一个运算符是聚合,它被分成两部分:并行前的聚合,然后是需要变成单个输入分区的最终聚合。我们可以在与连接相同的查询阶段执行此聚合的并行部分,因为第一个聚合不关心数据如何分区。然后来到第三个查询阶段,让我们现在开始调度执行。此查询阶段的输出仍然按客户 id 进行分区。
Query Stage #3: repartition=[]
HashAggregate: groupBy=[customer.id], aggr=[MAX(max_fare) AS total_amount]
Join: condition=[customer.id = order.customer_id]
Query Stage #1
Query Stage #2
最后一个查询阶段执行聚合,从前一个阶段的所有分区中读取数据。
Query Stage #4:
Projection: #customer.id, #total_amount
HashAggregate: groupBy=[customer.id], aggr=[MAX(max_fare) AS total_amount]
QueryStage #3
稍作回顾,下面是完整的分布式查询计划,其中显示了当需要在管道操作之间重新分区或交换数据时引入的查询阶段。
Query Stage #4:
Projection: #customer.id, #total_amount
HashAggregate: groupBy=[customer.id], aggr=[MAX(max_fare) AS total_amount]
Query Stage #3: repartition=[]
HashAggregate: groupBy=[customer.id], aggr=[MAX(max_fare) AS total_amount]
Join: condition=[customer.id = order.customer_id]
Query Stage #1: repartition=[customer.id]
Scan: customer
Query Stage #2: repartition=[order.customer_id]
Scan: order
Serializing a Query Plan 序列化查询计划
查询调度器需要将整个查询计划的片段发送给执行程序执行。
有许多选项可以用于序列化查询计划,以便在进程之间传递查询计划。许多查询引擎选择使用编程语言原生支持序列化的策略。如果不需要跨编程语言交换查询计划,那这无疑是一个合适的选择,而且这通常是最简单的实现机制。
然而,使用于编程语言无关的序列化格式是有好处的。Ballista 使用 Google 的 Protocol Buffers 格式来定义查询计划。该项目通常缩写为 "protobuf"。
下面是在 Ballista 的 protobuf 中定义的部分查询计划。
完整的源代码可以在 Ballista 的 github 仓库中找到。
译者注:由于 Ballista 现已移归到 Apache-Arrow 项目中,因此新的地址改为 https://github.com/apache/arrow-datafusion/blob/main/datafusion/proto/proto/datafusion.proto
message LogicalPlanNode {
LogicalPlanNode input = 1;
FileNode file = 10;
ProjectionNode projection = 20;
SelectionNode selection = 21;
LimitNode limit = 22;
AggregateNode aggregate = 23;
}
message FileNode {
string filename = 1;
Schema schema = 2;
repeated string projection = 3;
}
message ProjectionNode {
repeated LogicalExprNode expr = 1;
}
message SelectionNode {
LogicalExprNode expr = 2;
}
message AggregateNode {
repeated LogicalExprNode group_expr = 1;
repeated LogicalExprNode aggr_expr = 2;
}
message LimitNode {
uint32 limit = 1;
}
Protobuf 项目提供了用于生成特定语言源代码的工具 (protoc),以序列化和反序列化数据。
Serializing Data 序列化数据
数据在客户端和执行器之间以及执行器与执行器之间进行流传输的时候也必须进行序列化。
Apache Arrow 提供了一种 IPC(程间通讯)格式,用于在进程之间交换数据。由于 Arrow 提供了标准化的内存布局,因此可以直接在内存和输入/输出设备(磁盘、网络等)之间传输原始字节,而没有常规的与序列化相关的开销。这实际上是一个 zero copy 操作,因为数据不必从其所在内存中的格式,转换为单独的序列化格式。
但是,关于数据的元数据,例如 schema 模式(列名和数据类型)确实需要使用 Google Flatbuffers 进行编码。 此元数据很小,并且通常每个结果集或每个批处理序列化一次,因此开销很小。
使用 Apache Arrow 的另一个优点是,它在不同编程语言之间提供了非常有效的数据交换。
IPC 定义了数据编码格式,但是没有定义交换机制。例如,Arrow IPC 可以通过 JNI 将数据从 JVM 语言传输到 C 或者 Rust。
Choosing a Protocol 选择协议
既然我们已经为查询计划和数据选择了序列化格式,下一个问题是如何在分布式进程之间交换这些数据。
Apache Arrow 为此提供了一个 Flight 协议。Flight 是一种新的通用 C/S 框架,用于简化大型数据集在网络接口上高性能传输实现。
Arrow Flight 库提供了一个开发框架,用于实现可以发送和接收数据流的服务。Flight 服务端支持了几种基本类型的请求:
- Handshake: 一个简单的请求,以确定客户端是否被授权,在某些情况下,也可以建立一个实现定义的会话令牌,以供未来的请求使用
- ListFlights: 返回可用的数据流列表
- GetSchema: 返回数据流的模式
- GetFlightInfo: 返回关注的数据集的 “访问计划”,可能需要使用多个数据流。此请求可以接收包含特定应用程序参数的自定义序列化命令
- DoGet: 将数据流发送到客户端
- DoPut: 从客户端接收数据流
- DoAction: 执行特定于实现的操作并返回任意结果,即通用函数调用
- ListActions: 返回可用操作类型的列表
例如,GetFlightInfo 方法可用于编译查询计划并返回接收结果所需的信息,然后再每个执行器上调用 DoGet 以开始接收来自查询的结果。
Streaming 流
可以尽快提供查询结果,并将其流式传输到需要对该数据进行运算的下一个进程,这一点很重要,否则将出现不可接受的延迟,因为每个运算都必须等待前一个运算完成。
但是,有些运算符需要在产生任何输出之前接收所有输入数据。排序操作就是一个很好的例子。在接收到整个数据集之前,不可能对数据集进行完全排序。这个问题可以通过增加分区的数量来缓解,这样大量的分区可以并行排序,然后可以使用合并操作有效地组合排序后的批次数据。
Custom Code 自定义代码
通常需要将自定义代码作为分布式查询或计算的一部分来运行。对于单语言查询引擎,通常可以使用该语言的内置序列化机制在查询期间通过网络传输此代码,这在开发过程中非常方便。另一种方法式将编译后的代码发布到存储库,以便在运行时将其下载到集群中。对于基于 JVM 的系统,可以使用 maven 存储库。更通用的方法是将所有运行时的依赖打包到 Docker 镜像中。
查询计划需要提供必要的信息,以便在运行时加载用户代码。对于基于 JVM 的系统,这可以是一个类路径和一个类名。对于基于 C 的系统,这可能是一个共享对象的路径。无论哪种情况,用户代码都需要实现一些已知的 API。
分布式查询优化
与在单个主机上执行并行查询相比,分布式查询有很多额外开销,所以只有这样做有好处的时候才应该使用。关于这个画图ide一些有趣光电,我推荐阅读论文 Scalability! But at what COST?。
另外,有许多方法可以分发相同的查询,所以我们如何知道该使用哪一种呢?
其中一种解决方法是构建一种机制来确定执行特定查询计划的开销,然后为给定问题创建所有可能的查询计划组合的某个子集,并确定哪一个最为高效。
计算运算开销涉及到许多因素,并且涉及不同的资源和成本限制。
- Memory: 我们通常关心的是内粗你的可用性,而不是性能。在内存中处理数据要比在硬盘上读写快几个数量级。
- CPU: 对于可并行的工作负载,更多的 CPU 核心意味着更好的吞吐量
- GPU: 有些运算在 GPU 上要比 CPU 快几个数量级
- Disk: 硬盘的读写速度有限,云供应商通常会限制每秒 I/O 操作的数量 (IOPS)。不同类型的硬盘具有不同的性能特性(机械硬盘 vs SSD vs NVMe)
- Network: 分布式查询的执行涉及节点之间的数据流。网络基础设施限制了吞吐量
- Distributed Storage: 源数据存储在分布式文件系统 (HDFS) 或对象存储 (Amazon S3, Azure Blob Storage) 中,并且在分布式存储和本地文件系统之间传输数据是有开销的
- Data Size: 数据量大小也很重要。当在两个表之间执行连接并且需要通过网络传输数据时,最好传输两个表中较小的表。如果其中一个表可以装入内存,则可以使用更有效的连接操作
- Monetary Cost: 如果一个查询可以以三倍的成本加速 10%,那么这样做是否值得?当然,这个问题最好由用户来回答。通常通过限制可用的计算资源量来控制货币成本
如果提前知道足够多的数据相关信息,例如数据又多大、查询中使用的连接件的分区基数、分区数量等。那么可以使用算法预先计算查询成本。这一切都取决于查询的数据集的某些可用统计信息。
另一种方法是开始运行查询,并让每个运算符根据接收到的输入数据进行调整。Apache Spark 3.0.0 引入了一个自适应查询执行功能,它可以做到这一点。